python 爬虫利用urllib.request.urlretrieve() 保存图片在本地,图片没有内容
我用Jupyter Notebook爬取了需要保存的图片的url,但是利用urllib.request.urlretrieve() 将图片保存到本地,图片没有内容,该url使用360浏览器打开也是没有内容的图片(和我保存在本地一样),但是用goole打开就是正常的图片。
相关代码
url='http://www.jj20.com/bz/zrfg/d...'
response=urllib.request.urlopen(url)
html=response.read().decode('gb2312')
soup=BeautifulSoup(html,'lxml')
data=soup.select('body > div.wzfz.top-main.fix > div > ul.pic2.vvi.fix')
data2=re.findall('src="(.+?)" width',str(data))
data2 #此处得到了图片链接的一个列表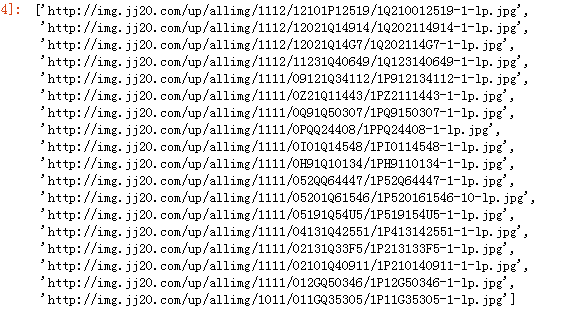
x=0
for itemm in data2:
print(itemm)
urllib.request.urlretrieve(itemm,'C:\Users\Administrator\Desktop\pachong2\%s.jpg'%x)
x+=1 #通过链接保存图片到本地
代码完毕,运行不报错,但保存的图片却是加密图片,如下 我用360浏览器打开这些url也是显示这个,但是用goole打开就是正常的图片。如下:
我用360浏览器打开这些url也是显示这个,但是用goole打开就是正常的图片。如下:
我百度了好多相关内容,但和别人的出错结果都不一样,想知道这种情况是怎么回事,为什么360浏览器打开是这样的,还有就是要怎么才能通过goole浏览器把图片下载下来呢。
←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
因为网站做了反爬,无法直接打开图片连接,还有User-Agent的身份验证,所以加入请求头去下载就可以了
import requests
s=requests.session()
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'www.jj20.com',
'If-Modified-Since':'Fri, 21 Dec 2018 03:58:29 GMT',
'If-None-Match':'"cf51d66ee198d41:0"',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
}
s.headers.update(headers)
url=r'http://img.jj20.com/up/allimg/1111/052QQ64447/1P52Q64447-1-lp.jpg'
html=s.get(url=url)
print(html.text)
with open('picture.jpg', 'wb') as file:
file.write(html.content)
原因:
网站做了防止盗链等反爬措施,导致不能直接通过链接爬取
解决办法
使用代理
如更换user-agant cookie referer等请求头
报错https的请求内容,会报ssl错误咋个解决呢?
url='http://www.jj20.com/bz/zrfg/d...'
修改为 url='http://www.jj20.com/bz/zrfg/
urllib.request.urlretrieve(itemm,'C:\Users\Administrator\Desktop\pachong2\%s.jpg'%x)
C:\Users\Administrator\Desktop\pachong2\ 这个文件夹是否存在?
我改为我电脑上有的文件夹,就正常了。可以时、现在没有了反爬机制吧
还有一句,
data=soup.select('body > div.g-box-1200 ')