html如何提取同级信息?
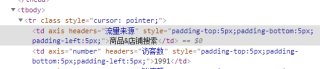

如上图,请教大佬如何提取出访客数1991的数据?我的想法是类似pandas中筛选表格的条件,假设这个表格为df
df[df['流量来源']=='商品&店铺搜索']['访客数']流量来源的商品店铺搜索我用的是下面代码获取的
sources = soup.find_all('td',{'headers':'流量来源'})
for source in sources:
s = source.get_text()请教大佬如何用python实现这种同级的信息提取?因为商品&店铺搜索没有在访客数的属性里,不知道应该如何操作
不知道理解问题对不对,希望能帮助到你。
对HTML格式内容,可以考虑使用XML方式解析,查找元素所对应的节点试试。
提去前端HTML页面里的数据也就是xpath、lxml、bs4这些吧,要不就去接口里找。
from lxml import etree
parse = etree.HTML(text=html)
tr = parse.xpath('//tr[@style="cursor: pointer;"]')
for td in tr:
x = parse.xpath('//td[@headers="流量来源"]/text()')[0]
y = parse.xpath('//td[@headers="访客数"]/text()')[0]

感谢各位大佬的回答,我不知道怎么回复评论就在这里再补充一下问题了。
@Daletxt:谢谢你的代码,但是其实类似的html块还有很多,您的这段代码提取y的时候应该如何识别是属于图里的直通车的“访客数”等数据还是“商品&店铺搜索”的数据?谢谢
<tbody>
<tr class="" style="cursor: pointer;">
<td axis="" headers="流量来源" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
商品&店铺搜索
</td>
<td axis="number" headers="访客数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
1991
</td>
<td axis="number" headers="销售额" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
1669.6
</td>
<td axis="number" headers="销售量" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
29
</td>
<td axis="number" headers="订单数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
28
</td>
<td axis="number" headers="转化率" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
1.41%
</td>
<td axis="" headers="" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
<a href="javascript:void(0);" onclick="showwirelesstrend('search.taoapp 商品&店铺搜索 20210110 uv 1'); return false;">
<img border="0" height="13" src="images/icon_trend.gif" width="15"/>
</a>
</td>
</tr>
<tr class="" style="cursor: pointer;">
<td axis="" headers="流量来源" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
直通车
</td>
<td axis="number" headers="访客数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
1981
</td>
<td axis="number" headers="销售额" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
342
</td>
<td axis="number" headers="销售量" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
234
</td>
<td axis="number" headers="订单数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
5432
</td>
<td axis="number" headers="转化率" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
34%
</td>
<td axis="" headers="" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
<a href="javascript:void(0);" onclick="showwirelesstrend('ztc.taoapp 直通车 20210110 uv 1'); return false;">
<img border="0" height="13" src="images/icon_trend.gif" width="15"/>
</a>
</td>
</tr>
<tr class="" style="cursor: pointer;">
<td axis="" headers="流量来源" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
淘内免费其他
</td>
<td axis="number" headers="访客数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
534
</td>
<td axis="number" headers="销售额" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
234
</td>
<td axis="number" headers="销售量" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
123
</td>
<td axis="number" headers="订单数" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
45
</td>
<td axis="number" headers="转化率" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
1.46%
</td>
<td axis="" headers="" style="padding-top:5px;padding-bottom:5px;padding-left:5px;">
<a href="javascript:void(0);" onclick="showwirelesstrend('otherfree.taoapp 淘内免费其他 20210110 uv 1'); return false;">
<img border="0" height="13" src="images/icon_trend.gif" width="15"/>
</a>
</td>
</tr>
</tbody>我把部分html贴在这里了,求大佬解答
import re
# 在所给的HTMl文本上
# 测试可以获取所需
regex='<td axis="" headers="流量来源" .*?>(.*?)</td>.*?headers="访客数".*?>(.*?)</td>'
tr_list=re.findall(regex,html,re.S)
for tr in tr_list:
# 元组
# print(tr)
# ('\n 商品&店铺搜索\n ', '\n 1991\n ')
# .....
print(tr[0].strip(),tr[1].strip())
# strip()去除前后空格
# 商品&店铺搜索 1991
# .....
# 输出结果
# 商品&店铺搜索 1991
# 直通车 1981
# 淘内免费其他 534