查网页源代码能发现某些内容,用代码方式却读取不到
https://m.chinaproled.en.alibaba.com/以该网页为例,通过查找源代码可以看到类似代码: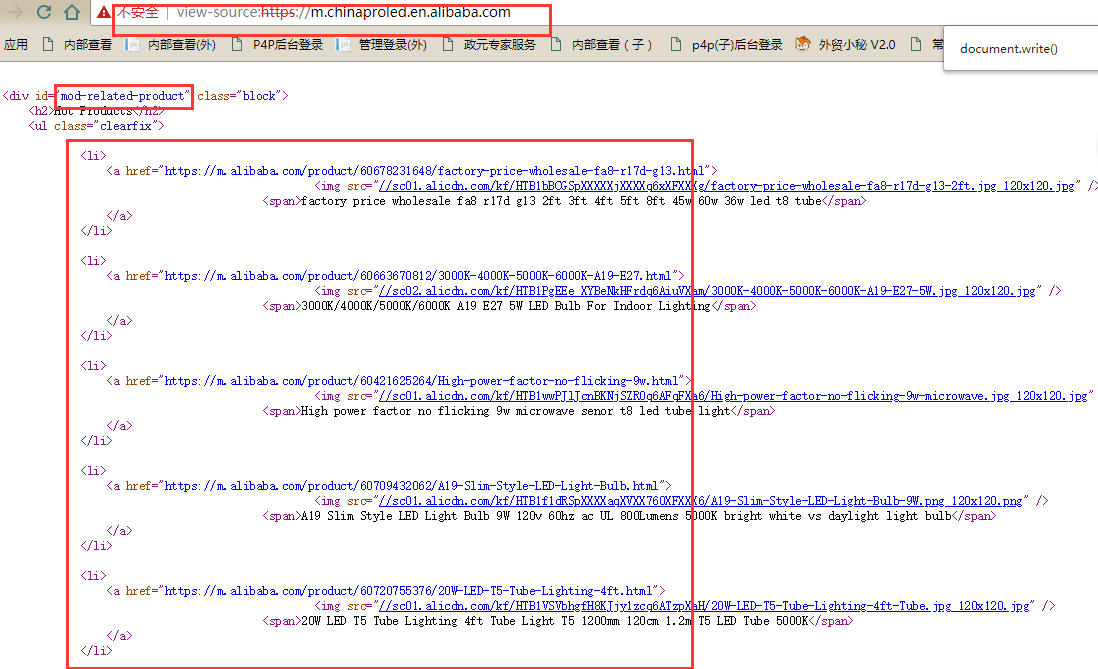
但是,如果使用HttpWebRequest类似代码的方式发起web请求,得到内容却是这样:
<div id="mod-related-product" class="block">
<h2>Hot Products</h2>
<ul class="clearfix">
</ul>
<a href="/productlist.html" class="all-products-link more-link">
View All Products
</a>
</div>
请问?这是什么技术,我用浏览器调试了,并没有发现什么异步的数据请求,另外像这种情况,如何通过代码的方式获取完整的内容?
响应的时候 有些东西是不返回的 只返回基础架构 如果像你这样全都能获取到 那么就不会有各种爬虫工具了。。。
https://m.chinaproled.en.alibaba.com/productlist.html?spm=a2706.8301167.topnav.2.1edc37899HBWMA
看我是怎么分析的:
这个取决于服务器端程序员写的。只要愿意,服务器可以给同一个URL返回不同的内容。比如登录之前和登录之后的HTML应该是不同的。
要获得正常的界面你就得反向工程服务器,用fiddler比较你自己发的请求和浏览器发的哪里有区别。
有时候就算你发的请求和用户手动操作一样,发送太频繁也可能被服务器的反爬虫机制抓到的。
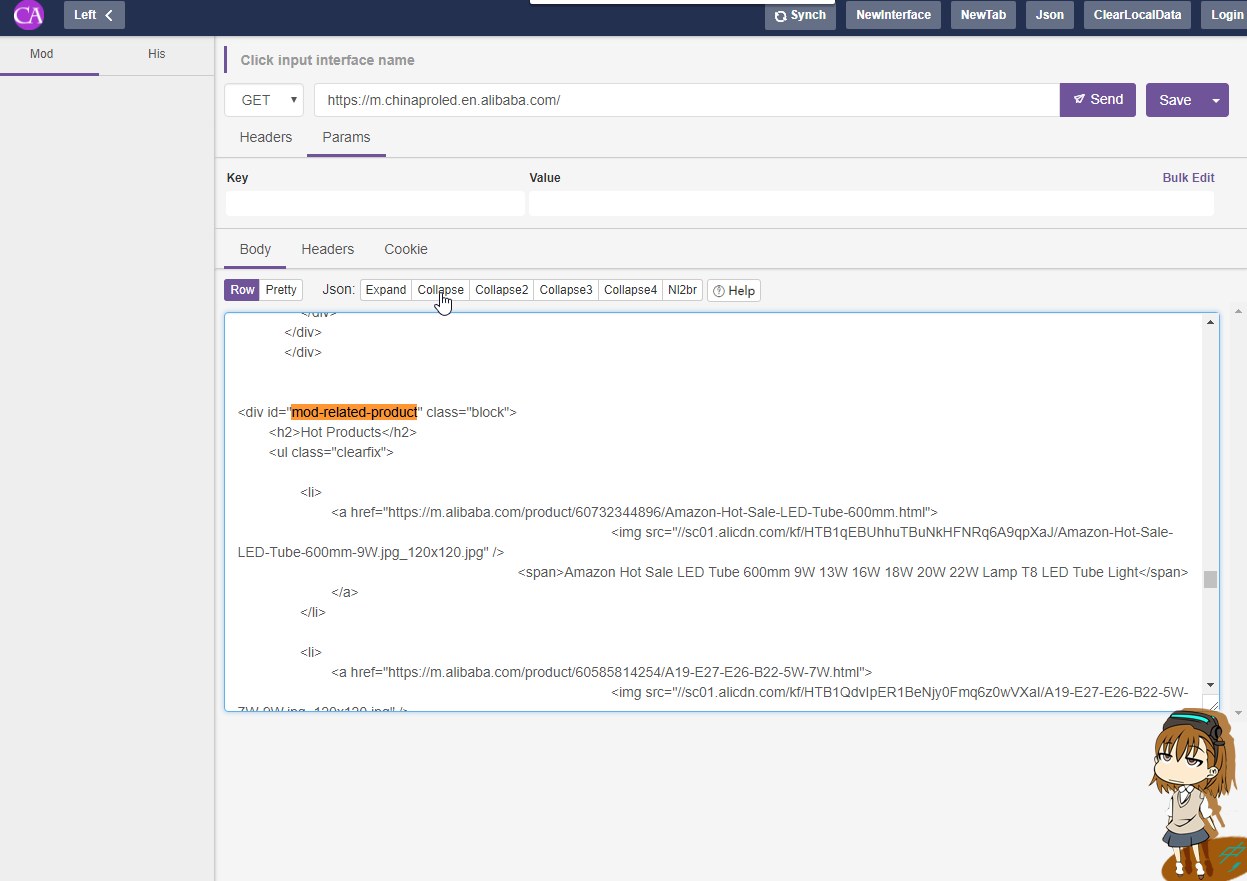
1)您好,我是一个美团外卖配送员,我来解决下您的问题,是这样的,除了使用浏览器的调试模式的netword抓包功能以外,其他的请您查看js,一般来说,我们的加载和渲染代码都是写在js里面的,这样可以更快的加载页面,也可以更安全的使用,推荐您按下 F12->Source 在左侧查看页面加载到的文件,要特别注意js文件。
2)修改:您好,看起来是可以直接获取的,请您尝试使用get的方式请求。
如果解决了您的问题,请点击采纳,如果并没有,请在下方留言,我会继续帮您解答。