使用正则表达式以及findall查询结果有问题
我想解析百度贴吧某个贴子各楼层内容
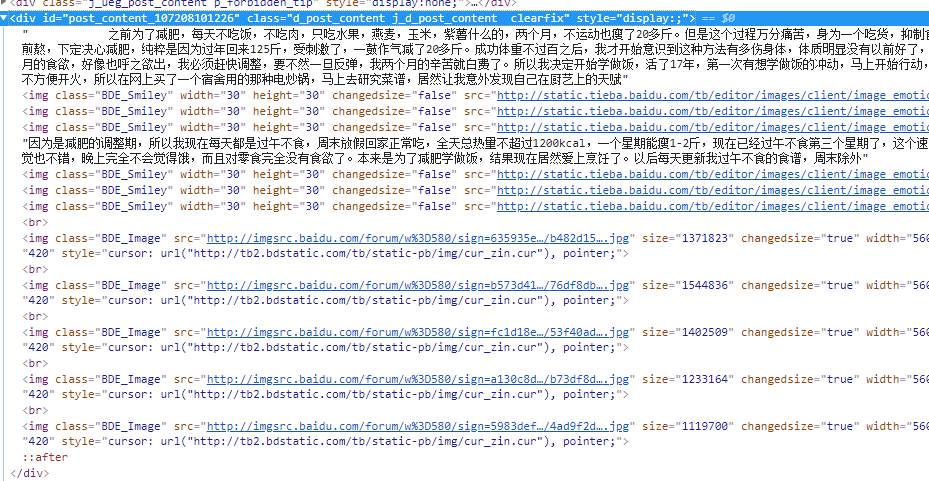
html元素是这样:
之前为了减肥,每天不吃饭,不吃肉,只吃水果,燕麦,玉米,紫薯什么的,两个月,不运动也瘦了20多斤。但是这个过程万分痛苦,身为一个吃货,抑制食欲真的是一种煎熬,下定决心减肥,纯粹是因为过年回来125斤,受刺激了,一鼓作气减了20多斤。成功体重不过百之后,我才开始意识到这种方法有多伤身体,体质明显没有以前好了,而且压抑了两个月的食欲,好像也呼之欲出,我必须赶快调整,要不然一旦反弹,我两个月的辛苦就白费了。所以我决定开始学做饭,活了17年,第一次有想学做饭的冲动,马上开始行动,因为一个人住,不方便开火,所以在网上买了一个宿舍用的那种电炒锅,马上去研究菜谱,居然让我意外发现自己在厨艺上的天赋 因为是减肥的调整期,所以我现在每天都是过午不食,周末放假回家正常吃,全天总热量不超过1200kcal,一个星期能瘦1-2斤,现在已经过午不食第三个星期了,这个速度非常合适,感觉也不错,晚上完全不会觉得饿,而且对零食完全没有食欲了。本来是为了减肥学做饭,结果现在居然爱上烹饪了。以后每天更新我过午不食的食谱,周末除外>
因为是减肥的调整期,所以我现在每天都是过午不食,周末放假回家正常吃,全天总热量不超过1200kcal,一个星期能瘦1-2斤,现在已经过午不食第三个星期了,这个速度非常合适,感觉也不错,晚上完全不会觉得饿,而且对零食完全没有食欲了。本来是为了减肥学做饭,结果现在居然爱上烹饪了。以后每天更新我过午不食的食谱,周末除外>
我的用法:
patternContent = re.compile('
(.*?)
(.*?)', re.S)或者
patternContent = re.compile('
好像因为文字里有html代码 乱套了 我在这重新说明一下哈
贴吧html元素:
我的用法

上面这种打印不出来数据
然后改成一个以上分组,这样:

就能打印出每楼层数据了
求助:
使用findall时 正则表达式必须有一个以上分组么?
findall没有匹配也是可以的
你可以先打印出html,看是不是有换行,如果有换行的话是是不可以用(.*?)来匹配的
"text1"\n([\S\s]*?)\n"text2"
这样来匹配换行的内容
本来想帮你测试的,但是你这样提问,没有给源码出来,测试成本太大,只能靠你自己了
https://tool.lu/regex/
你可以在这个网站上测试,再写代码