html 中的#document后面的内容为什么爬不下来
我想爬http://skyserver.sdss.org/dr7/en/tools/explore/obj.asp?id=588848900446814264这个网页中的数据
但是我用urllib.request.urlopen打开之后里面的#document里面的东西却没有,不知有没有什么方法爬?
你爬这个页面吧。
http://skyserver.sdss.org/dr7/en/tools/explore/summary.asp?id=0x082c02f481830038&spec=0x011ac9ca7b800000
step1: 获取 HTML 源代码
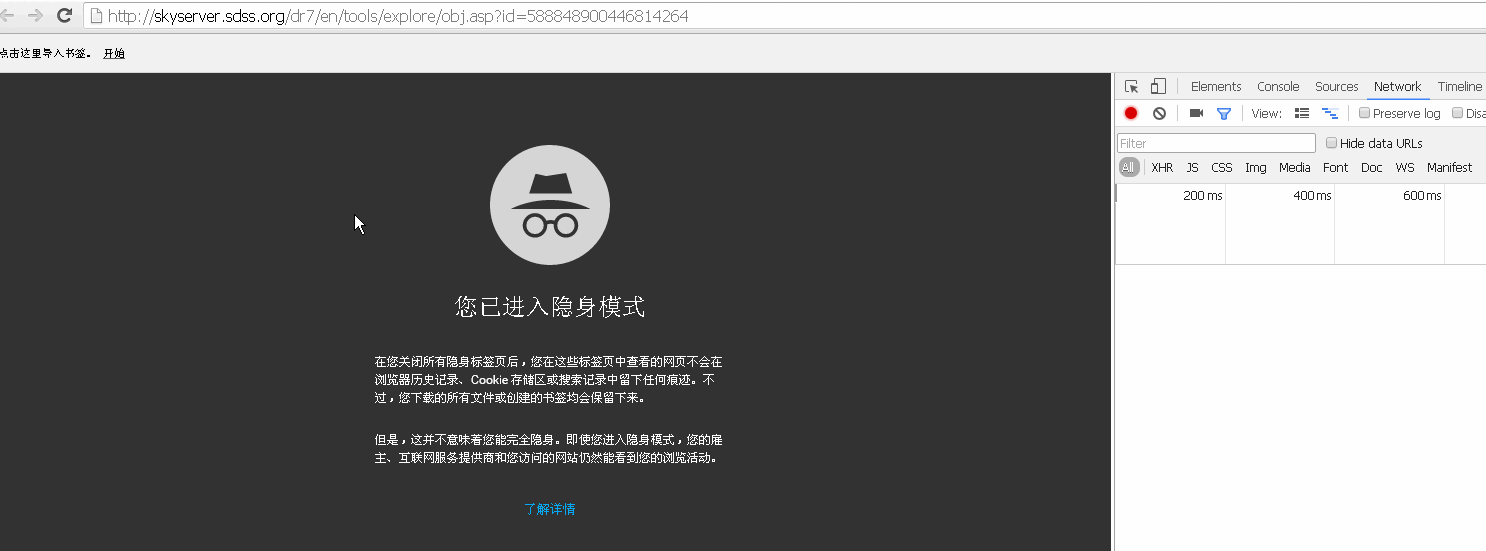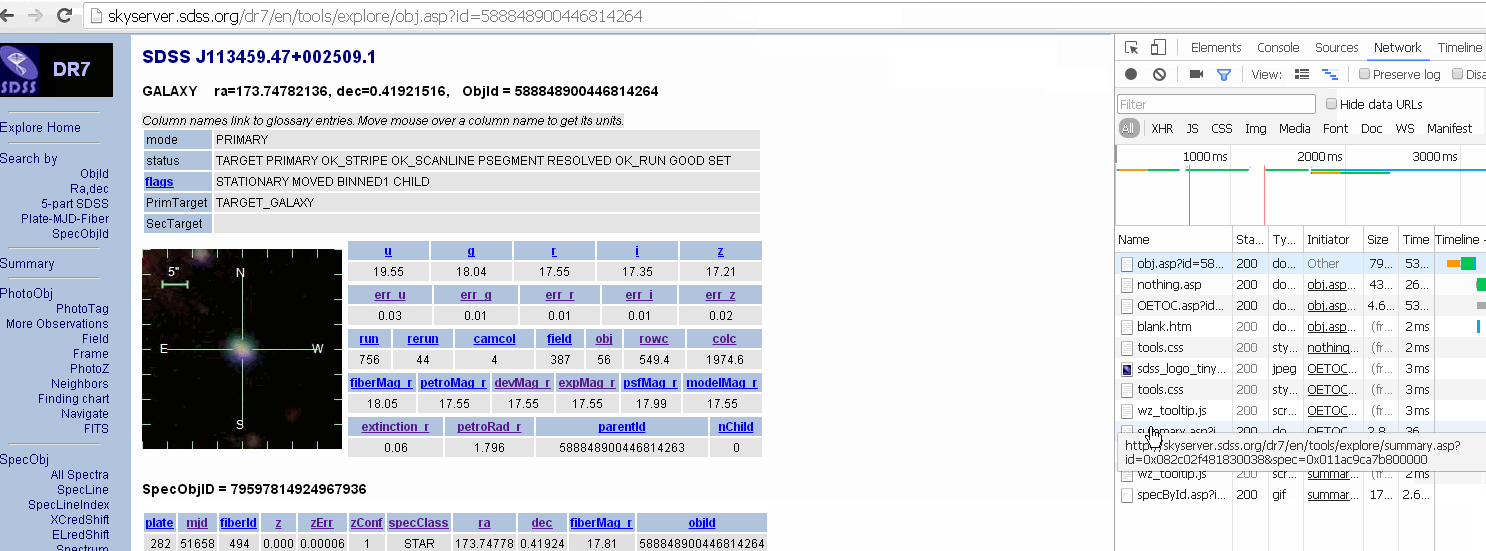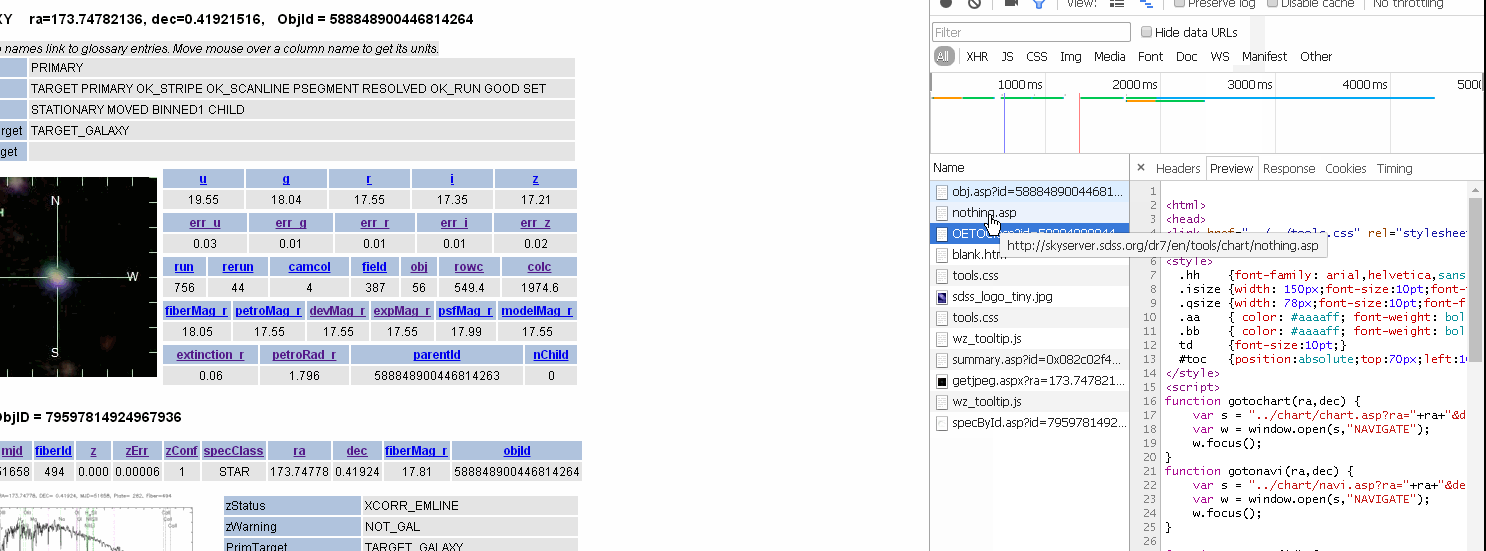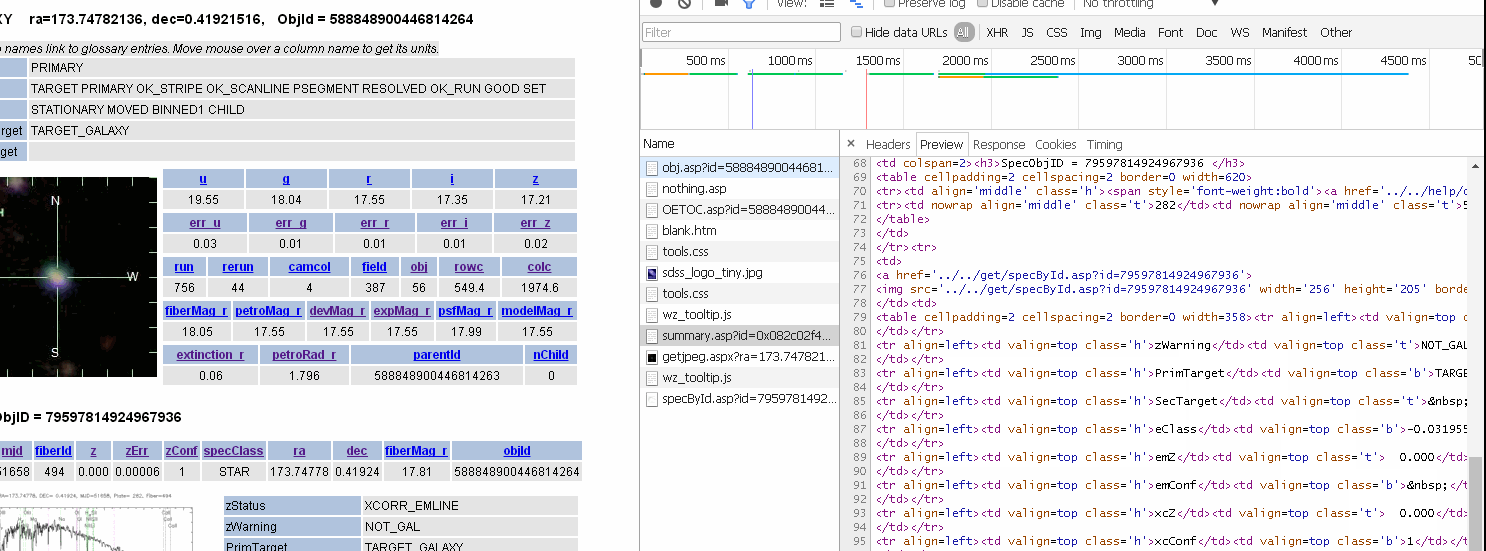
http://skyserver.sdss.org/dr7/en/tools/explore/obj.asp?id=588848900446814264
step2: 获取到 frame 的 src 属性,得到新页面链接
http://skyserver.sdss.org/dr7/en/tools/explore/OETOC.asp?id=588848900446814264
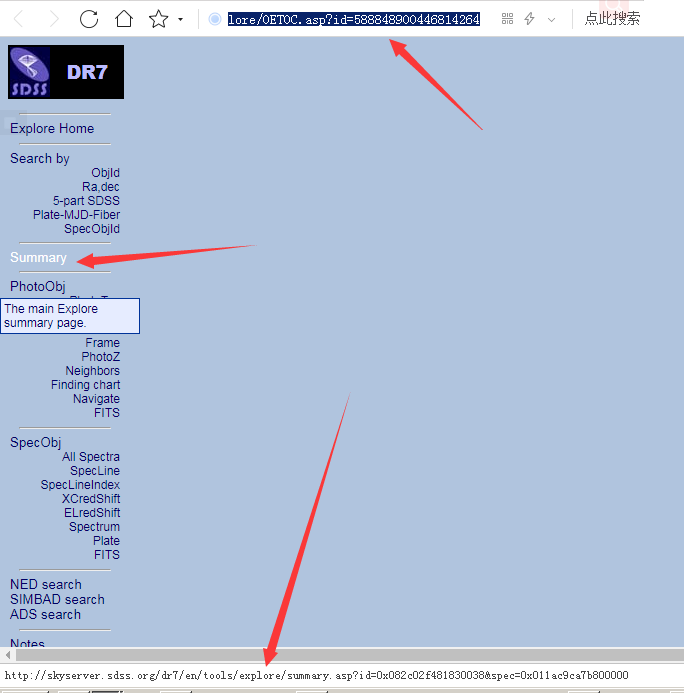
step3: 获取
<tr><td align="left"><a href href属性,最后得到完整的路劲
http://skyserver.sdss.org/dr7/en/tools/explore/summary.asp?id=0x082c02f481830038&spec=0x011ac9ca7b800000
因为这些内容是异步加载的,你可以用chrome浏览器按照我下面的方法抓包分析: