为什么python爬虫程序下载的图片不正确?
import re
import urllib.request
def open_url(url):
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134'
headers={'User-Agent':user_agent,'Referer':'http://www.mmjpg.com/mm/1317'}
reg=urllib.request.Request(url,headers)
response=urllib.request.urlopen(url)
html=response.read()
return html
def craw(url,page):
html=open_url(url)
html1=str(html)
pat1='<div class="content" id="content">.+?<div class="page" id="page">'
result1=re.compile(pat1).findall(html1)
result1=result1[0]
pat2='<div class="content" id="content"><a href=".*"><img src="(.+?.jpg)"'
imagelist=re.compile(pat2).findall(result1)
for each in imagelist:
print(each) #能够正确抓取图片地址
imgname=each.split('/')[-1]
fandler=open('D:/files/download/'+imgname,'wb')
data=open_url(each)
fandler.write(data)
fandler.close()
for i in range(1,49):
url='http://www.mmjpg.com/mm/1317/'+str(i)
craw(url,i)
爬虫能够正确抓取图片的地址,但下载在电脑上的图片如下: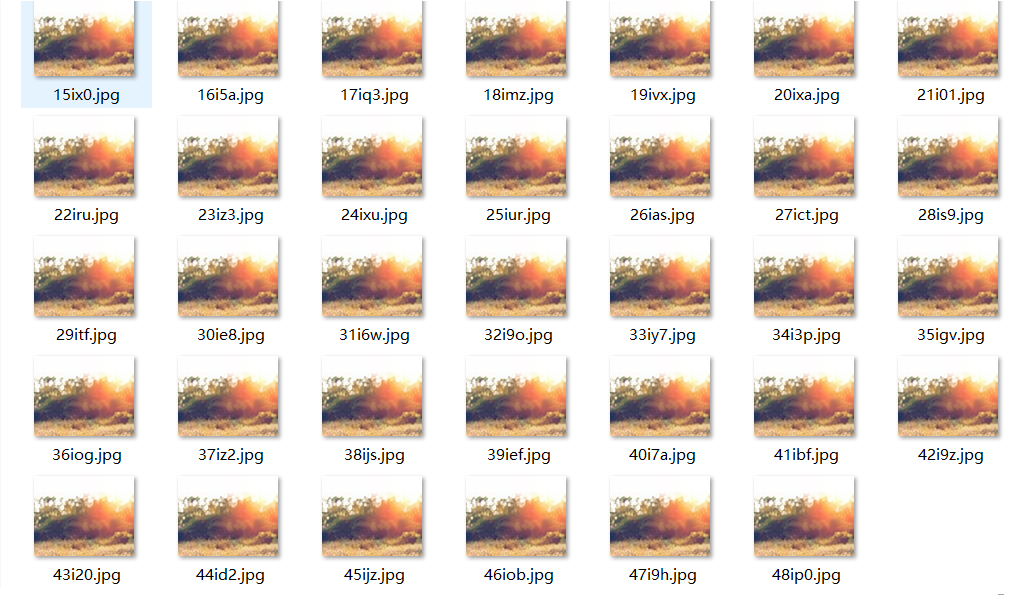
请教高手原因出在哪?
图片地址做了反爬,你直接复制图片地址在浏览器上打开就是你下载下来的图片,所以你需要在请求图片网址时,data=open_url(each) 你的headers错误了,应该是headers={'User-Agent':user_agent,'Referer':'http://www.mmjpg.com/mm/1317''+str(i)}