利用python 爬取淘宝网页,应该是find_all后有问题,运行没有结果
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item J_MouserOnverReq "):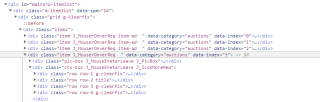
给你提供个思路:你可以一级一级往上推,看看到底是哪一级获取不到内容,如果能获取到你再看看你要的那个标签名字和你直接从网页复制到的是不是一样,有时候从网页直接复制到的格式和通过代码抓取到的会有差异,至于为啥会有差异我也不懂。。。
楼上说的对,动态数据跟静态有区别的
如果是静态与动态区别,你可以尝试使用python的selenium库来解决,相关selenium库的使用,可以查看我爬虫的专栏里面有selenium库的使用方法。