MySQL根据两列进行去重
有一个表如下: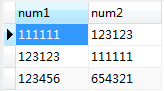
想要的查询结果为: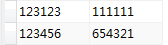
即根据num1和num2这两个字段进行去重,不论它们的先后顺序。比如:num1=111111,num2=123123和num1=123123,num2=111111就是重复的,去重并保留一条记录。
这个是ID是自增序列的做法,有点复杂,如果你的ID是UUID的话这个方式还是有问题。
SELECT
*
FROM
tt
WHERE
ID NOT IN (
SELECT
*
FROM
(
SELECT
t1.ID
FROM
tt AS t1
INNER JOIN tt AS t2 ON t1.a = t2.b
AND t1.b = t2.a
AND t1.ID != t2.ID
GROUP BY
t1.id + t2.id
) AS t
)
如果按照这个写法中途遇到了group by的错误执行下面语句
-- 修改mysql中的group by 要求查询字段全部在group by后的设置
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
如果不是自增ID的话,我在想想还有什么别的写法
select distinct a.* from 表 a where a.date = ( select max(b.date) from 表 b where b.name = a.name and b.code = a.code )
你是要查询去重复吗?SELECT * FROM A WHERE A.num1 NOT IN (SELECT num2 FROM a);
先子查询自身关联,查询出两列交叉相同的数据ID,在查询不在这个ID集合中的便是去重的数据,不知能否满足你的需求
SELECT
*
FROM
tab
WHERE
ID NOT IN (
SELECT
t1.ID
FROM
tab AS t1
INNER JOIN tab AS t2 ON t1.a = t2.b
AND t1.num1 = t2.num2
AND t1.num2 != t2.num1
)
刚贴错了一点,好尴尬,哈哈哈
SELECT
*
FROM
tab
WHERE
ID NOT IN (
SELECT
t1.ID
FROM
tab AS t1
INNER JOIN tab AS t2 ON t1.ID ID != t2.ID
AND t1.num1 = t2.num2
AND t1.num2 = t2.num1
)
select * from a where a.num1 in(select distinct a1.num1 from a1) and a.num2 not in(select distinct a1.num1 from a1)
先把第一列去重查出来,然后第一列的字段包含去重后的字段,第二列的字段不包含去重后的字段,就是你想要的不重复的
我也遇到了的问题,想了很久,突然灵感来了,用一个num1 > num2 来去掉重复数据
你品,你细品