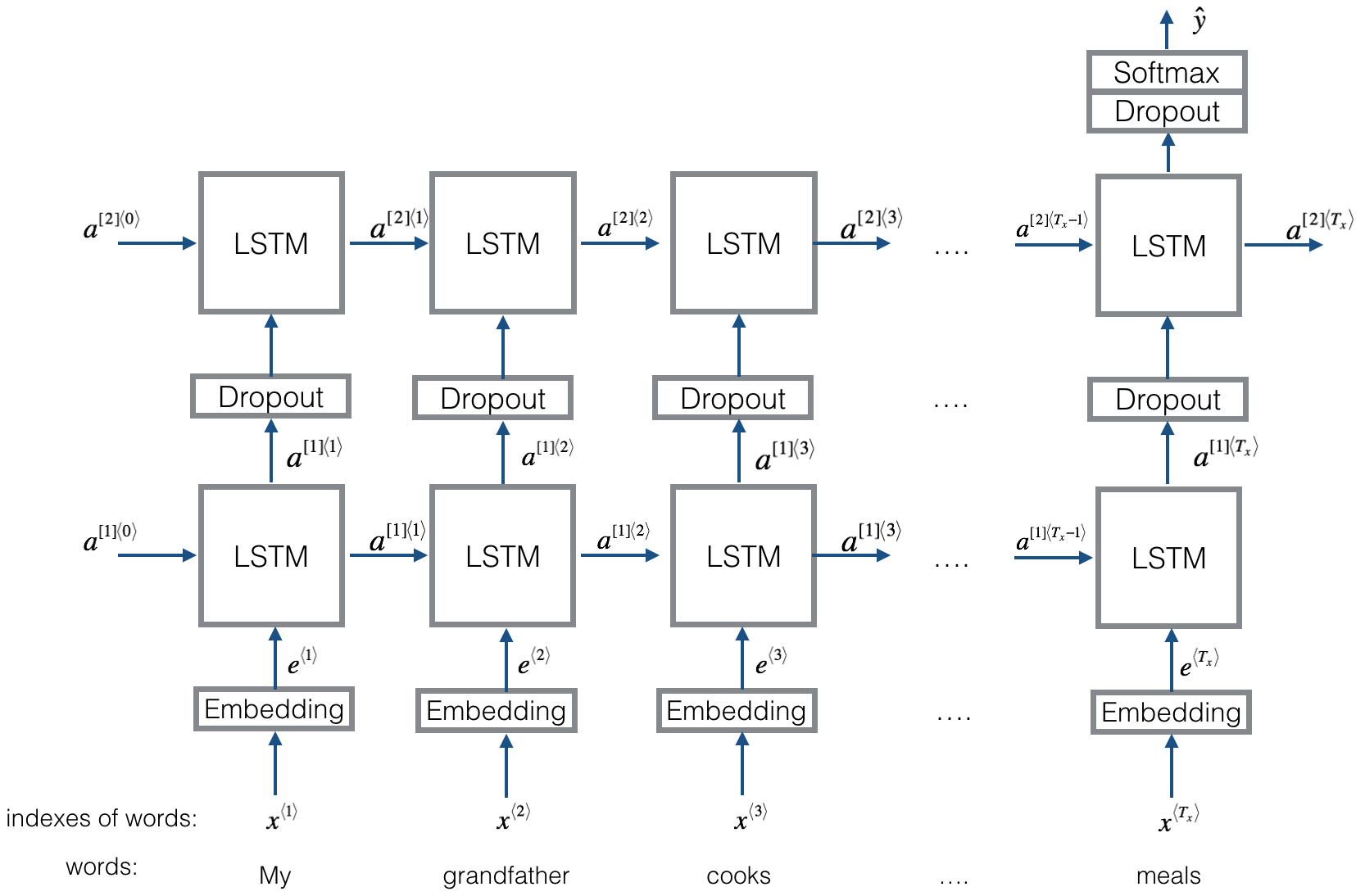
关于RNN的一些细节问题?
有两个问题:
1.RNN的dropout在一个序列的每个时间step是固定的还是变化的?
2.embedding将onehot向量转化为稠密向量,这个过程为啥要+1如下所示
embedding = tf.get_variable("embedding", [len(words)+1, rnn_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement)
emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
dropout可以插入在任何地方。它随机让一些神经元断开防止过拟合,dropout放在那里,每批数据起作用的是随机变化的。
没看到图。onehot就是有几个分类(比如词向量)就有几个维度,然后某一项是1,别的都是0。不知道你说的+1是什么。