算法:考察二分算法的平均成功查找长度1.5logn是如何计算出来的,请看图


 我想知道谁看懂了那个递推分析的过程,尤其是那个递推式。。。能给我讲解一下吗
我想知道谁看懂了那个递推分析的过程,尤其是那个递推式。。。能给我讲解一下吗
你说的是C(k)那个递归式吗?如果是的话请看下面的一张图片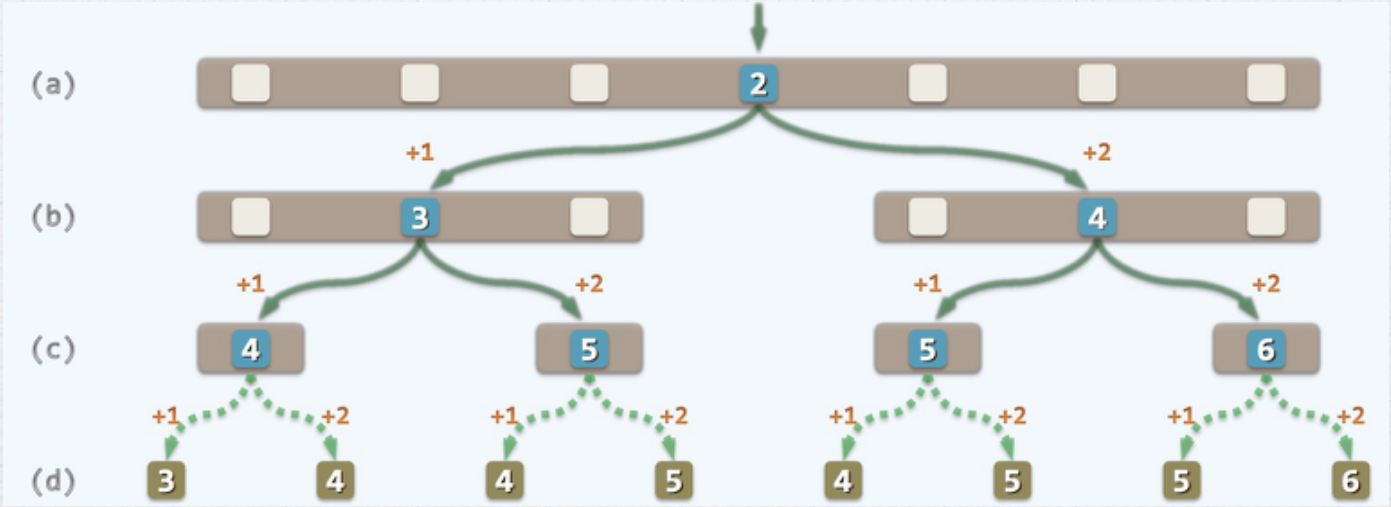
我们将(a)那一层想象成第k层,下面的(b)看作是k-1层。我们把第k层删掉,那么第k-1层就变成了顶层。
k-1层有两个分支,一左一右。你应该不难看出,顶层的查找长度(也就是一次查找成功的查找长度)必然是2。
那么对于左面的k-1层来说它的顶层是3,右面的顶层是4。稍加观察你会发现左面的k-1层的所有元素的查找长度都会相对于以k-1层为顶层时的查找长度多1。同样右面的k-1层的所有元素查找长度会相对于以k-1层为顶层时的查找长度多2。所以C(k)中需要把这些长度补上,然后在加上第k层的查找长度2即为C(k).
每次迭代有三种可能;查找失败则返回-1,这个版本的代码很直观,但是也有一些缺陷:
每次迭代的判断次数不平衡,有可能只需判断一次,也有可能要判断两次;
有多个元素命中时,不能保证返回秩最大(或者最小)者;
查找失败时,不能指示失败的位置;
针对第一个问题,我们这里要提出一个概念,叫作查找长度;
我们在进行二分查找的迭代过程所涉及的计算,无非两类:元素比较大小和秩的算数运算及赋值。元素的秩是整数,它的操作属于O(1)复杂度的基本操作,而元素比较大小一般来讲也是O(1)复杂度的基本操作,但是我们说当向量的元素类型很复杂时,其比较操作未必能保证在常数时间内完成!因此就时间复杂度的常系数而言,元素比较操作的权重远远高于秩的运算和赋值,而查找算法的整体效率也更主要地取决于元素比较操作的次数,即所谓的查找长度。
接下来我们以长度为7的向量为例,分析其成功查找长度和失败查找长度:(涉及的具体证明可以查阅原书)
每一个成功查找所对应的查找长度,仅取决于向量的长度n以及目标元素所对应的秩,而与元素的具体数值无关,因此我们可以得出,n = 7时,各元素所对应的成功查找长度和失败查找长度分别为:
{4, 3, 5, 2, 5, 4, 6} 平均为4.14;
{3, 4, 4, 5, 4, 5, 5, 6} 平均为4.50;
我们可以看出,迭代次数相同的情况下对应的查找长度不尽相同!这就是所谓的不平衡,那么对于更加一般的情况(n = 2^k - 1),我们采用递推分析法:
递推式:C(k) = [C(k-1) + (2^(k-1) - 1)] + 2 + [C(k-1) + 2 * (2^(k-1) - 1)]
C(k)是查找长度;
[C(k-1) + (2^(k-1) - 1)] 代表经过一次成功的比较,查找范围深入到左侧部分;
2 代表经过两次失败的比较,命中要查找的元素;
[C(k-1) + 2 * (2^(k-1) - 1)] 代表经过一次失败的比较和一次成功的比较,查找范围深入到右侧部分;
最终我们可以得出平均查找长度为O(1.5logn);对于失败查找长度同样可以得出为O(1.5logn);
折半查找长度推导
可以看一下我写的这个博客,如果有问题可以留言继续讨论一下。我这个博客主要也是参考了洋Key的答案。
以上图为例,C(k)代表以向量中所有元素为查找终点的总查找成功长度,**强调所有元素**。
当计算C(k)与C(k-1)的关系时,这里看的是图中(a)层和(b)层,当(a)向(b)转变时,要计算a,b之间的两个向下的箭头(左+1,右+2)
但是虽然只画出这两个箭头,但实际上在查找过程中这两个并不是各自只进行了一次,以左边的箭头为例来讨论:
左边查找成功的例子有3个,分别以4,3,5为终点,实际查找过程为(2——>3,2——>3——>4,2——>3——>5)
实际上左边这个箭头进行了3次,即以**左边各元素为查找成功终点**的过程都必须经过2——>3,
因此C(k) = [C(k-1) + (2^(k-1) - 1)] + 2 + [C(k-1) + 2 * (2^(k-1) - 1)]中左边中括号中会出现(2^(k-1) - 1),是**左边元素的个数**
右边过程的分析同理
首先,每个元素要么查1次继续迭代,要么查2次继续迭代,要么查两次结束。
此时,总次数为
[2^(k-1)-1]*1+[2^(k-1)-1]*2+2
之后,继续迭代查找长度要加上2*C(k-1)
所以总次数
C(K)=c(K-1)+[2^(k-1)-1]+c(K-1)+[2^(k-1)-1]*2+2