python爬虫如何自动获取Network中的某个XHR地址?
需要获取机场航班数据
该机场的url地址https://zh.flightaware.com/live/airport/KHRL
其航班数据是动态加载进来的,通过F12并刷新后得到
https://zh.flightaware.com/ajax/ignoreall/trackpoll.rvt?token=c35ca45ecbca57cd1ea443d1c65c36426ea06630de026ffd737977e4a40a26ead614b3f2ddde9907453c214a859f7965-88dd7c1a0d41355dafa2ce4ff0e607704b11c422c13281778f5b552d40a619d4c5559546eb9966e7-501878875ac23bacc59c19453f7939a79b200f0e&locale=zh_CN&summary=0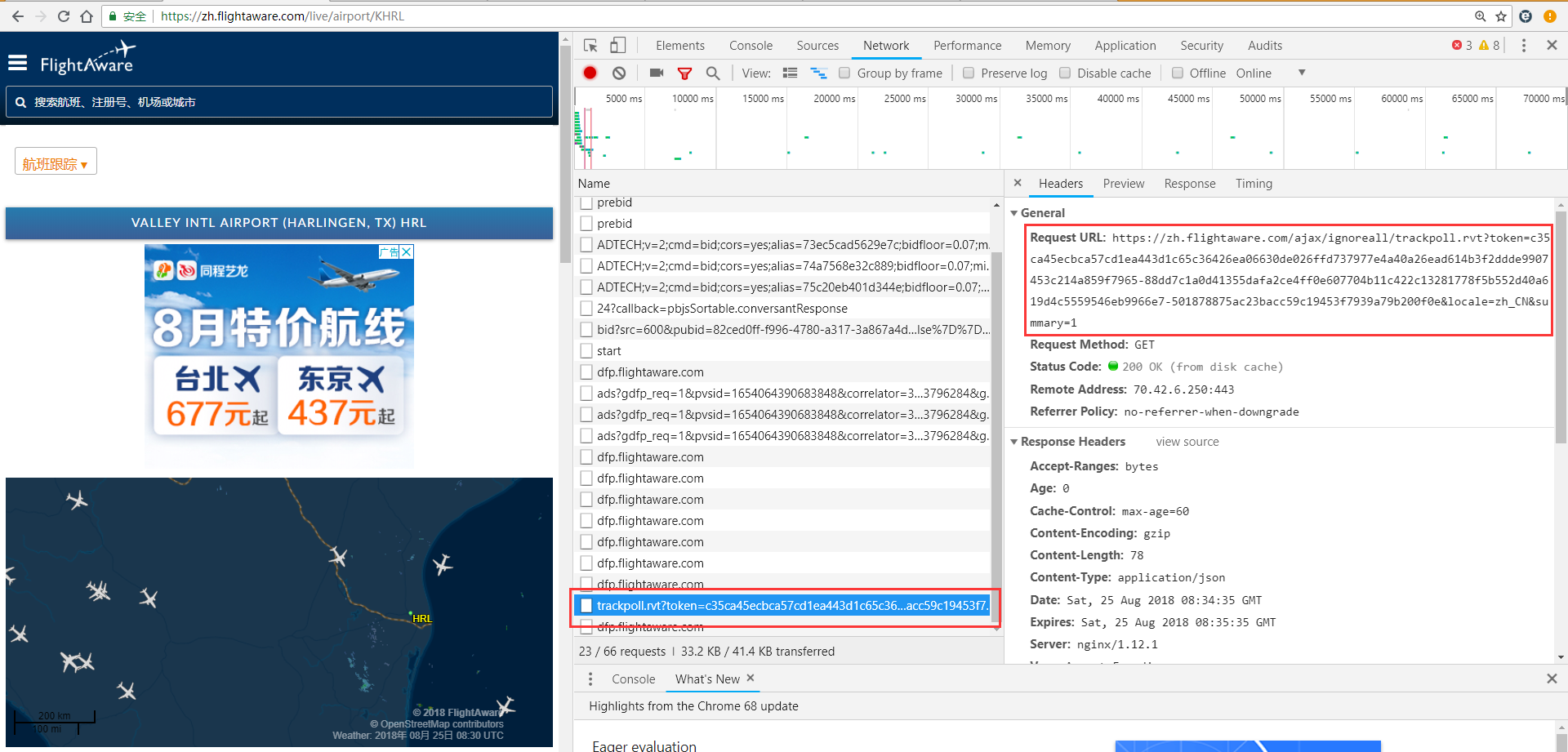
现在的问题是我有数千个机场的url地址,手动F12找到每个机场的航班地址是无法想象的,所以有没有方法自动获得每个机场请求航班数据的那个URL?
万望大神有空瞅瞅!感谢!
楼主问的可能有点不清楚,我的理解是:https://zh.flightaware.com/live/airport/+{机场代号} 楼主有几千个机场代号,需要爬取这几千个URL的https://zh.flightaware.com/ajax/ignoreall/trackpoll.rvt 的内容,这个XHR有3个参数,locale,summary,token;locale,summary这两个是固定的;而token获取的方法:
打开https://zh.flightaware.com/live/airport/+{机场代号} 查看网页源代码 搜素 var trackpollGlobals = 就可以找到token的值了,
那爬虫代码就是先爬取https://zh.flightaware.com/live/airport/+{机场代号} 网页,获取token值后再结合locale,summary值就可以爬取目标XHR内容了
emmm本来昨天想回答来着,结果因为敏感词被禁言了,跟楼上的想法差不多。
另外,还有一个比较笨的方法,源代码里有一段js代码包裹着的json数据,函数名是trackpollBootstrap,它无需token,只需要一个航hangban代号,比如https://zh.flightaware.com/live/flight/RPA3625中的‘RPA3625’。获取所有航班可以从所有hangkong公司下手,遍历每个公司所有的航班的代号,所有公司的信息在一个js文件里,在network的js中可以看到‘airlines-js.rvt’,下划线好像也不让发,自己将两个横线改成下划线。然后对数据自己做一些处理都行。
可以通过 Browsermob-Proxy 获取到,具体可以参考我写的这篇文章:https://blog.csdn.net/qq_32502511/article/details/101536325#comments_12013853