navicat for mysql导入txt文本出现数据库条数和文本条数不一致
将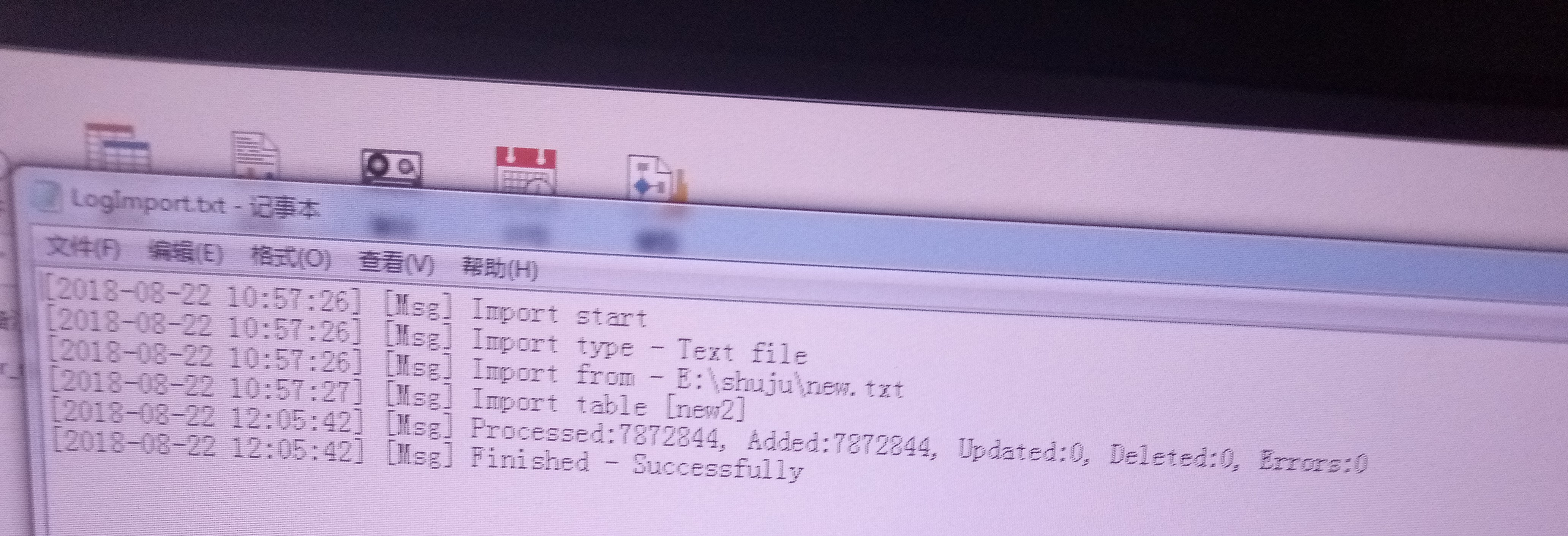 txt文本导入数据库,过程并没有报错,到时和文本的行数不一致,
txt文本导入数据库,过程并没有报错,到时和文本的行数不一致,
文本大概有千万条,数据库只有几百万条,这是什么原因?
麻烦讲一下,谢谢。尽量详细些。
有可能是因為分割符設置有問題,如果你的分割符號設置錯誤,那系統可能會以一大片的文字作為一個數據塊,所以實際導入的條數就會出現問題。還有,雙引號在導入文本中是很特殊的,可能是因為你的文本中存在雙引號,所以會出現你這樣的狀況。
或者是因為這個文件本身的問題。
當然,也有可能是navicat這個sql客戶端自身的問題,我用的是OSX系統的navicat premium,我感覺不是非常穩定,不知windows上navicat的感覺如何。
這些也僅僅是猜測,因為你沒有報告任何關於文件和你的導入設置,我無法進行推理。希望這些能幫到你。
文本信息大概是这样
aaaa,bbbb,cccccc,dddd, , eeeeee,hhhhhhh
11111,22222,33333,444444,,55555,666666
................................
当然这里面数字,汉字,字母符号等都有
我用pilotedit查看有千万条,但是count(*)总数只有几百万条
如果你沒有用utf-8來保存,那麼導入進去的應該都是亂碼。如果不是亂碼,那麼說明編碼是沒有問題的。
aaaa,bbbb,cccccc,dddd, , eeeeee,hhhhhhh
11111,22222,33333,444444,,55555,666666
這是你展示的文本信息,你需要注意第一行與第二行之間的符號是否為換行符,你可以試試把紀錄分隔符改成CRLF,這是windows系統的默認值;
並且你要看看你的文本中有沒有出現你文本限定符設置的符號。
還有,可以貼一些圖上來嗎?
嗯,你看看這個吧,關於紀錄分隔符的解釋:
https://blog.csdn.net/echo_follow_heart/article/details/48314523