java将一个文本的数据插入另一个文本的指定位置
现在有个问题,我有一个文本,上面的数据不全,需要将另外一个文本的数据插入,以id号的顺序插入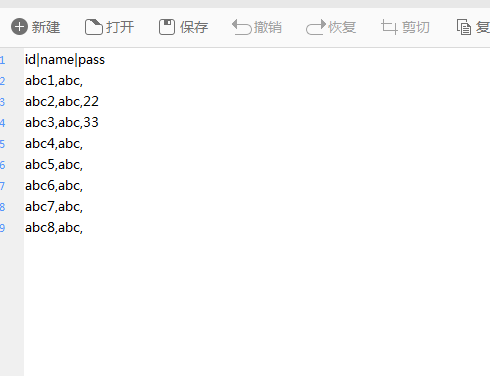
上面的是不全的文本,下面的是需要插入的文本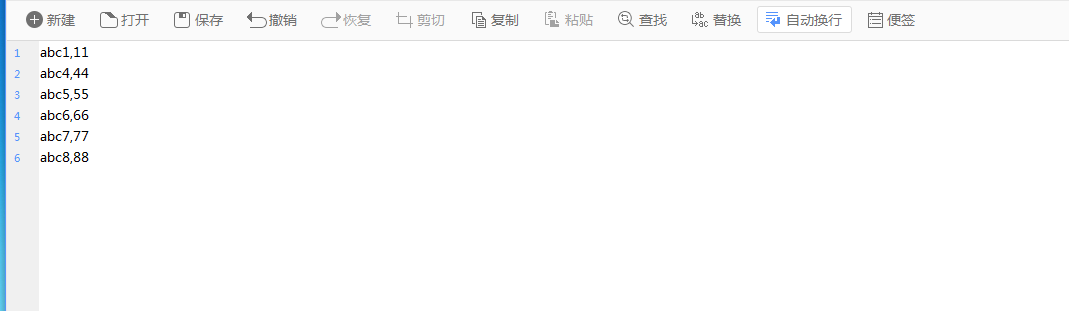
最后是这样的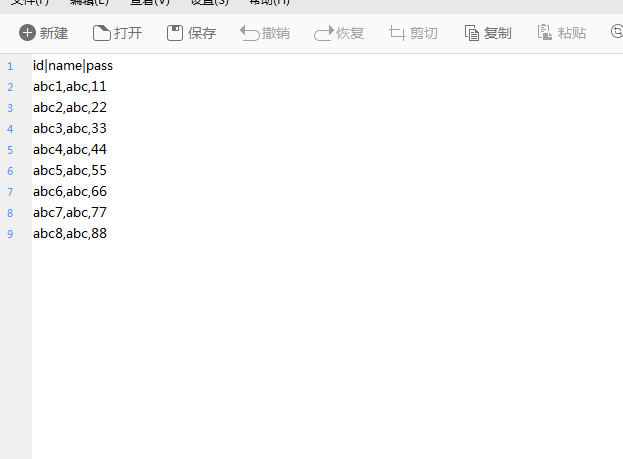 ,如果第一个文本,即不全的文本数据量比较大,还需要用上面方式来处理?
,如果第一个文本,即不全的文本数据量比较大,还需要用上面方式来处理?
package design;
import org.yaml.snakeyaml.reader.UnicodeReader;
import java.io.*;
import java.util.*;
public class ReadTxt {
public static List<Map<String,String>> readFromLockingTxt(String fileName) {
BufferedReader reader = null;
List<Map<String,String>> mapList = new ArrayList<Map<String,String>>();
try{
FileInputStream fileInputStream = new FileInputStream(new File(fileName));
UnicodeReader unicodeReader = new UnicodeReader(fileInputStream);
reader = new BufferedReader(unicodeReader);
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
Map<String,String> map = new LinkedHashMap<String,String>();
System.out.println("line " + line + ": " + tempString);
tempString.trim();
if(line==1){
String [] strs = tempString.split("\\|");
map.put("id",strs[0].trim());
map.put("name",strs[1].trim());
map.put("pass",strs[2].trim());
}else{
//替换多个空格
String string = tempString.replaceAll(" {1,}", "");
String [] strs = string.split(",");
map.put("id",strs[0].trim());
map.put("name",strs[1].trim());
if(strs.length == 3){
map.put("pass",strs[2].trim());
}else{
map.put("pass","");
}
}
mapList.add(map);
line++;
}
reader.close();
}catch (IOException e){
e.printStackTrace();
}finally {
if (reader != null){
try{
reader.close();
}catch (IOException e1){
e1.printStackTrace();
}
}
}
return mapList;
}
public static Map<String,String> readFromKeyTxt(String fileName) {
BufferedReader reader = null;
Map<String,String> map = new LinkedHashMap<String,String>();
try{
FileInputStream fileInputStream = new FileInputStream(new File(fileName));
UnicodeReader unicodeReader = new UnicodeReader(fileInputStream);
reader = new BufferedReader(unicodeReader);
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
System.out.println("line " + line + ": " + tempString);
tempString.trim();
//替换多个空格
String string = tempString.replaceAll(" {1,}", "");
String [] strs = string.split(",");
map.put(strs[0].trim(),strs[1].trim());
line++;
}
reader.close();
}catch (IOException e){
e.printStackTrace();
}finally {
if (reader != null){
try{
reader.close();
}catch (IOException e1){
e1.printStackTrace();
}
}
}
return map;
}
public static void writeListToTxt(List<Map<String,String>> list,String fileName){
StringBuilder sb = new StringBuilder();
for(int i=0;i<list.size();i++){
if(i==0){
sb.append(list.get(i).get("id")+"a\u007C"+list.get(i).get("name")+"a\u007C"+list.get(i).get("pass")).append("\r\n");
}else{
sb.append(list.get(i).get("id")+","+list.get(i).get("name")+","+list.get(i).get("pass")).append("\r\n");
}
}
try{
FileWriter writer = new FileWriter(fileName);
BufferedWriter bw = new BufferedWriter(writer);
bw.write(sb.toString());
bw.close();
writer.close();
}catch(Exception e){
e.printStackTrace();
}
}
public static boolean isEmpty(String s) {
return ((s == null) || (s.length() == 0));
}
}
package design;
import java.io.File;
import java.util.List;
import java.util.Map;
public class App {
public static void main(String args[]){
//读取缺失的文件
List<Map<String,String>> lockMapList = ReadTxt.readFromLockingTxt("D:"+ File.separator+"workspace"+File.separator+"lacking.txt");
System.out.println("修改前list为:"+lockMapList);
//读取补充文件
Map<String,String> keyMap = ReadTxt.readFromKeyTxt("D:"+ File.separator+"workspace"+File.separator+"key.txt");
System.out.println("需要插入的文本为:"+keyMap);
//组合成新的完整的list
lockMapList.parallelStream().forEach(p->{
if(ReadTxt.isEmpty(p.get("pass"))){
p.replace("pass",keyMap.get(p.get("id")));
}
});
System.out.println("组合后list为:"+lockMapList);
//重组完成后的List存储到txt文件
ReadTxt.writeListToTxt(lockMapList,"D:"+ File.separator+"workspace"+File.separator+"whole.txt");
}
}
以逗号splite一下,第一列有相同的就合并成一行
// 每一行是一个对象 我就简写了哈
public class objM {
Long id;
String name;
Long pass;
}
// 要替换的行按照 key是name、value是pass 放入一个map
Map map = New HashMap<>();
//如果pass为空 就用map中key对应pass填值
if(objM.getPass() ==""){
String key = objM.getName();
Long newPass = objM.setPass(map.get(key));
objM.setPass(newPass);
}
然后再把所有的对象(行)输出到文本
1、如果有数据库,把第一个文本存到数据库里面,第二个文本通过update的方式更新
2、如果没有数据库,首先解析第一个文本,id作为key,name以及pass作为list 封装成map>的变量
第二个文本每行解析出id以及pass,通过getKey方式获取list并list.add
最后将map数据重新写到新的文件中。
3、如果第一个文本量比较大,则需要分批次读取和写入新的文件
文本量比较大的话,就需要分批次读取旧文件,一边读,一边写入新文件,
读到要插入文本的地方,就把文本插入之后写入新文件,然后接着读一部分旧文件,写一部分新文件,一直到结束。
可执行
String txt1 = "txt1.txt";//文件1
String txt2 = "txt2.txt";//文件2
String newFile = "txt3.txt";//合并后的文件
Map<String, List<String>> txtMap1 = new TreeMap<String, List<String>>();//可对id排序的map
Map<String, List<String>> txtMap2 = new TreeMap<String, List<String>>();
//读取txt1
BufferedReader br1 = null;
try {
String data = null;
br1= new BufferedReader(new InputStreamReader(new FileInputStream(txt1), "utf8"));
while((data = br1.readLine()) != null) {
data = data.trim();
if (data.trim().isEmpty()) {
continue;
}
String[] values = data.split(",", -1);//-1不限制长度,不会舍弃末尾的空值
String id = values[0];
String name = values[1].trim();
String pass = values[2].trim();
List<String > list = new ArrayList<String>();
if (!name.isEmpty()) {
list.add(name);
}
if (!pass.trim().isEmpty()) {
list.add(pass);
}
txtMap1.put(id, list);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (br1 != null) {
br1.close();
}
}
//读取txt2
BufferedReader br2 = null;
try {
String data = null;
br2= new BufferedReader(new InputStreamReader(new FileInputStream(txt2), "utf8"));
while((data = br2.readLine()) != null) {
data = data.trim();
if (data.trim().isEmpty()) {
continue;
}
String[] values = data.split(",");
String id = values[0].trim();
String pass = values[1].trim();
List<String > list = new ArrayList<String>();
if (!pass.isEmpty()) {
list.add(pass);
}
txtMap2.put(id, list);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (br2 != null) {
br2.close();
}
}
PrintStream ps = null;
try {
ps = new PrintStream(newFile);
for(Entry<String, List<String>> entry : txtMap1.entrySet()) {
String id = entry.getKey();
List<String> vs = entry.getValue();
if (vs.size() < 2) {
vs.addAll(txtMap2.get(id));
}
String data = id + "," + vs.get(0) + "," + vs.get(1);
ps.println(data);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (ps != null) {
try {
ps.flush();
} catch (Exception e) {
}
try {
ps.close();
} catch (Exception e) {
}
}
}
1、如果有数据库,把第一个文本存到数据库里面,第二个文本通过update的方式更新
2、如果没有数据库,首先解析第一个文本,id作为key,name以及pass作为list 封装成map>的变量
第二个文本每行解析出id以及pass,通过getKey方式获取list并list.add
最后将map数据重新写到新的文件中。
3、如果第一个文本量比较大,则需要分批次读取和写入新的文件
不知道题主说的数据量大具体是多大呢?
如果量比较小,不写代码,直接用excel就可以完成。
或者,采用工具,比如navcat for mysql一类的,直接把文本(可以直接导入txt文件)导入两张表中,关联查询就可以得到结果。
如果数据量大
又要考虑性能的话,可以采用redis,两个文件直接导入,用id作为key值,导入第一个文件,直接放入。
导入第二个文件,先去redis拿数据,拿到就补全剩下数据。两个文件全部导入,遍历所有key即可得到完全的数据,性能也有保证。
其实写代码也是一样的思路,无非一个放在内存里面,一个放在redis里面。
采用的数据结构为Map,key值为id,model,可以自定义一个model类,先去map里面拿数据,拿到就补全,拿不到就放入。