Jmeter中压力测试关于线程组的问题
我测试的是项目中的查询按钮。我模拟了10个请求
我把10个请求放在一个线程中,聚会报告结果如下: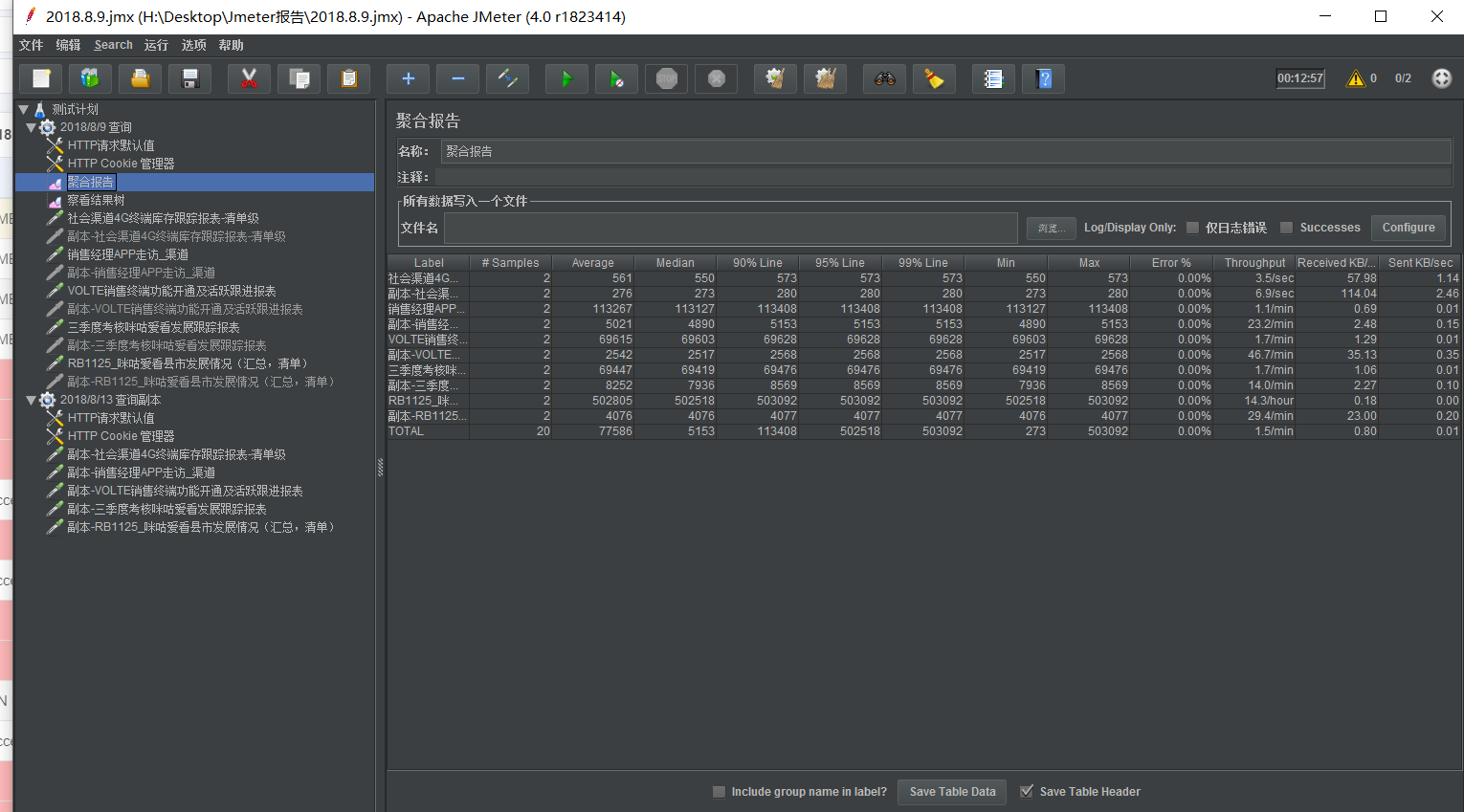
之后我把这10个请求分成了2个线程组,5个请求一组,聚合报告结果如下:

最后我把这10个请求中分成了6个线程组,请求名带副本两字的请求,一个副本一个线程组,这里有5个线程组,之后把没有带副本2字的5个请求放在一个线程组。
聚合报告结果如下:
我的疑问有几下几点(副本就是和正本的url路径相同):
第一点,我把10个请求放在同一个线程组里,配置的相同路径的2张相同的报表,只是查询数据库的SQL语句条件不一样,但是查询的时间会差距很大,但是我后面给他设置了2个线程组,副本和正本的查询时间就会相近。这是为什么。
第二点,我在这里设置了多个线程组,也就是第三种情况,副本跑完这5个路径的时间比正本放在一个线程组跑完5个路径的时间会快很多,这里的时间指的是线程组的运行时间。然后查询的平均时间会有一定的差距,那么我在模拟用户的并发情况的时候,我是把所有请求放在一个线程组里好,还是一个请求放在一个线程组好。
第三点,吞吐量是不是和数据库查询时间有关系,那么我到底怎么测试才可以压测到临界值。同一个报表,不一样的sql语句,也就是说同一个url后面带的参数不同,测出来的吞吐量差距也会有不同,这时候我怎么知道临界值。
没人回答的话说说我的理解,有错勿喷。
第一点,查询时间差距大是因为处理数据量不一样,线程组处理一样的语句时间应该几乎一样才对,涉及到操作系统处理任务问题。
第二点,线程组相当于用户操作,模拟用户并发应该一个请求一个线程组。
第三点,吞吐量与查询时间无太大关系,一秒钟处理的数据就这么多,你多少个用户也是一样的,测临界值可以模拟多用户单请求,单用户多请求,
多用户多请求。还有临界值机器配置不够是测不准的,数据库还没到临界值估计你的机器就跑满CPU了。