c#怎么获取网页上title的值
我想获取打开网站上的title的值“正式受理”,并将这个值写入Excel,应该怎么做,请各位大神赐教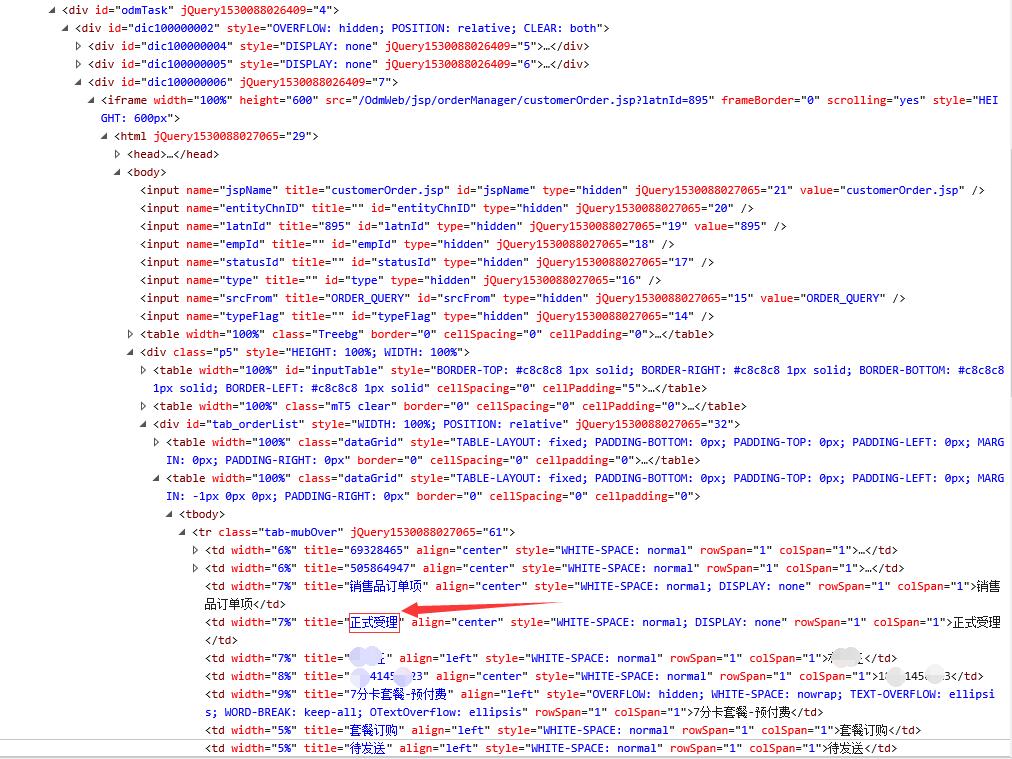
这是我写的代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace MyAutoM
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
//检测是否打开指定网页
mshtml.HTMLDocument doc = getInternetExploer("http://135.64.132.8").Document;
//获取title的值“正式受理”,请各位大神帮我补充一下
}
public static SHDocVw.InternetExplorer getInternetExploer(string url)
{
var shell = new Shell32.Shell();
var windows = (SHDocVw.IShellWindows)shell.Windows();
SHDocVw.InternetExplorer ie;
foreach (object window in windows)
{
ie = window as SHDocVw.InternetExplorer;
if (ie != null &&
string.Equals(System.IO.Path.GetFileName(ie.FullName),
"iexplore.exe", StringComparison.CurrentCultureIgnoreCase))
{
if (ie.LocationURL == url)
{
return ie;
}
}
}
return null;
}
}
}
干嘛不用webrequest直接下载iframe加载的页面,前后前后截取下就行了
只能获取到html的源代码。 在winform项目中,使用webbrowser控件,使用控件属性document,就可以得到托管的文档对象。类似js dom的。取HTML就是document.getElementbyName("html")[0].innerHTML。 或者,使用webclient.download(网页路径),直接下载html,临时保存后,再File.open,读出源文件。 webform里,同webclient。 前台,使用js,异步方式得到的,己经是html,试试便知,不再描述。
直接请求获取页面的内容,然后通过正则表达式进行提取,感觉你的html有一定格式,使用这个方案好些
先请求得到页面,用webclient或者httpwebrequest之类的 然后用xpath提取就行 xpath都不需要自己写 直接用谷歌浏览器右键检查 copy xpath
大佬您好,方便加个联系,将您这个程序发来参考吗?我想抓取网页中表格的文本。 抓取网页源代码,解析文本。https://s8hwxkltn6.jiandaoyun.com/dash/5f48d400a25baa0006034c29
大佬您好,请问,网页抓取数据的程序还有吗?https://s8hwxkltn6.jiandaoyun.com/dash/5f48d400a25baa0006034c29
我想抓取网页源代码,解析文本。得到网页中表格的数据