kafka 集群高可用测试
先搭建了3个kafka集群
3台都启动 并且正常发送消息后 测试 某一台挂了情况
#当前机器在集群中的唯一标识,和zookeeper的myid性质一样
broker.id=0
#当前kafka对外提供服务的端口默认是9092
listeners=PLAINTEXT://192.168.1.252:9092
#这个是borker进行网络处理的线程数
num.network.threads=3
#这个是borker进行I/O处理的线程数
num.io.threads=8
#发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
#kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
#这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
############################# Log Basics #############################
#消息存放的目录,这个目录可以配置为","逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,
#如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/usr/local/kafka_2.11-1.1.0/data/kafka/logs
#默认的分区数,一个topic默认1个分区数
num.partitions=3
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
#
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
#这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
#每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
#设置zookeeper的连接端口
zookeeper.connect=192.168.1.252:2181,192.168.1.253:2181,192.168.1.254:2181
# 超时时间
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
创建了 主题

然后 发送消息
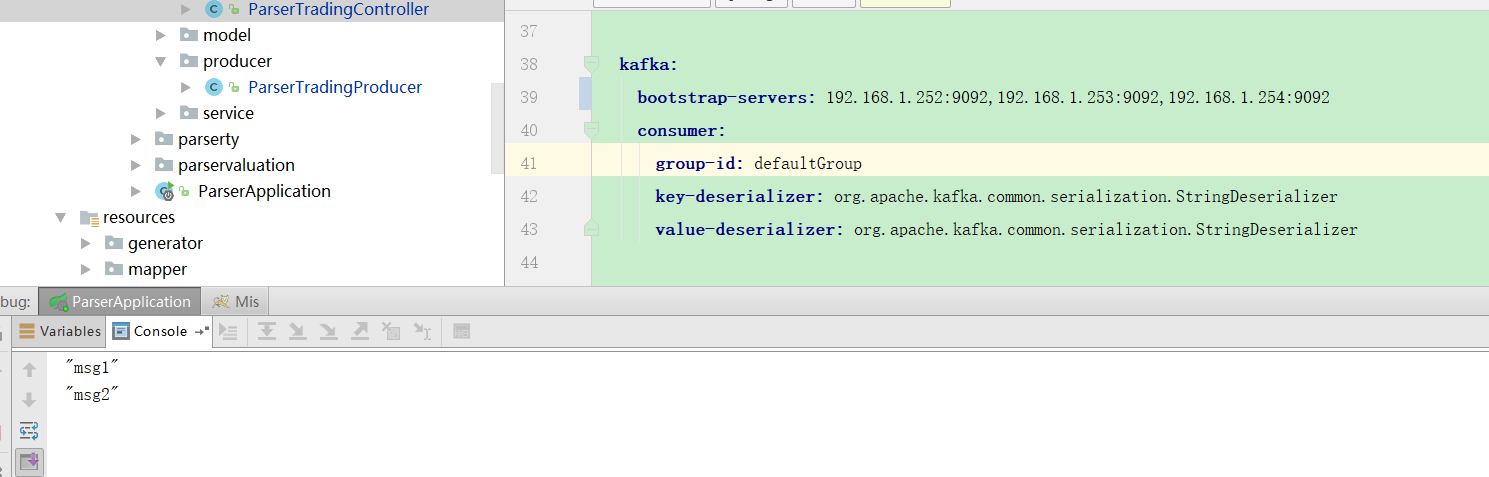
msg1
msg2
然后 关闭其中一台kafka
控制台打印
2018/05/15-13:48:03 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator- Marking the coordinator 192.168.1.254:9092 (id: 2147483645 rack: null) dead for group defaultGroup
2018/05/15-13:48:03 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator- Discovered coordinator 192.168.1.254:9092 (id: 2147483645 rack: null) for group defaultGroup.
2018/05/15-13:48:04 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator- Marking the coordinator 192.168.1.254:9092 (id: 2147483645 rack: null) dead for group defaultGroup
然后继续发消息
msg3
控制台无响应
继续发送msg4
无响应
重启那台kafka
控制台打印
"msg4"
"msg3"
2018/05/15-13:52:11 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] WARN org.apache.kafka.clients.consumer.internals.Fetcher- Received unknown topic or partition error in fetch for partition trading-1. The topic/partition may not exist or the user may not have Describe access to it
2018/05/15-13:52:11 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator- Marking the coordinator 192.168.1.254:9092 (id: 2147483645 rack: null) dead for group defaultGroup
2018/05/15-13:52:11 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] WARN org.apache.kafka.clients.consumer.internals.ConsumerCoordinator- Auto offset commit failed for group defaultGroup: Offset commit failed with a retriable exception. You should retry committing offsets.
2018/05/15-13:52:11 [org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator- Discovered coordinator 192.168.1.254:9092 (id: 2147483645 rack: null) for group defaultGroup.
kafka 不是主从复制么 不是谁挂了 用另一个么
你有启动了三台机器的服务??
监控这三台服务器了吗
使用jps是可以看到kafka进程的,你截图看出来只有个zookeeper服务啊
我目前对这个也有些疑问,百度了一些资料,好像说是 kafka要去zookeeper那注册, 消费者连zookeeper,而生产者是直连kafka的, 消费者通过zookeeper分配的kafka服务可以确保高可用,但是生产者往KAFKA发消息 如果坏掉一台 是不是会出问题。拿python测过 消费者直连kafka坏掉一台就收不到消息了。