在使用python的DataFrame新建一列时遇到问题
1cfame是frame的视图吗?
2请问是什么问题导致的,是因为在视图上创建新列cframe['os']引起的吗?
3请问解决这个问题的思路是怎样的,有哪些方法,哪个方法最优!
4那个tring 是这样写的吗?cframe.loc[:,'os']=....,但是这样写问题同样存在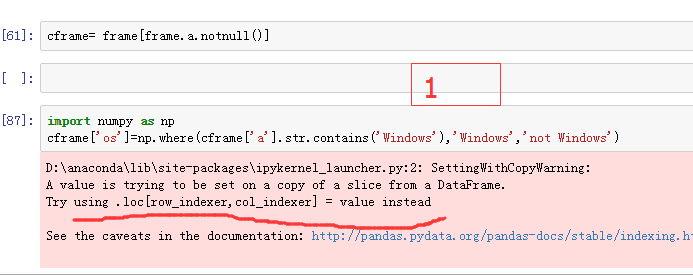
有X个机组以15分钟为步长的长系列(年月日时分)出力的数据,想处理成每个机组的,以“年月日”为索引值,每行显示1天96个点出力的形式。
先利用df.head()把dataframe按96切割成Y份,然后将Y份的第x列(x号机组的出力)提取出来,放到list里,再利用concat将list合并为新的dataframe,将该dataframe的列名更改为长系列(年月日),再转置,就可以得到想要的格式。
- 已知某元素索引位置,选取该元素
dataframe 如下,记为df
输入 df.loc['索引名称‘’,‘列名称’] 即可,例如
若没有index或列名称,则使用df.iloc[]在对应位置输入索引位置即可。
- 删除多行/多列
使用的前提是,dataframe的index和columns用的是数字,利用了drop()和range()函数。
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
axis = 0,表示删除行; axis = 1 表示删除列。
想删除多行/列,用range即可,比如要删除前3行,drop(range(0,3),axis = 0(默认为零,可不写))即可。
用dataframe.drop()可以删除,默认inplace = false, 即默认只是删除视图,如果要真的删除数,输入inplace=True.
【注意】inplace=True 删除后index也变了。
这个是cookbook对drop的解释:
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html
- 多个dataframe中选取列,合并为1个新的dataframe
用到了
1)删除dataframe索引,重新赋予从0开始的索引;
df.reset_index(drop=True,inplace = True), drop = True表示会删除原来的旧索引,否则默认会在原dataframe新增一列;
2)利用concat将一系列dataframe合并,参考了 https://zhuanlan.zhihu.com/p/27577410
pd.concat(listhere,axis=1,join_axes = [listhere[0].index]), listhere指要被合并的dataframe们,axis = 1表示按列合并,
join_axes 设定了合并的起始点,所以要注意保证每个dataframe的索引值一致,否则会按设定的join_axes合并,其他dataframe如果没有这个索引值,就会赋值NAN。
3)更改dataframe列的名称,利用df.columns = list 。
控制输出为年-月-日的格式
数据缺漏的插补
数据格式是以一分钟为步长的长系列负荷,从数据库读入excel后存在缺漏情况,即并不是每一天的数据都有1440个点。需要把数据处理成15分钟间隔,即1天有96个点。
Step1. 在excel中,新建一张sheet,第一列索引用excel自动填充,处理成目标范围以1分钟为步长的时间序列,作为index。然后使用vlookup在原始数据中比对index,这样缺漏行会自动返回#NAN值。【由于本身计算精度问题,可能出现两张表上同一个日期转为数值后存在百亿分之一的误差,可先采用rounddown()处理一下,取小数点后8位数字就可以了】
这一步也可以利用dataframe的merge来操作,没研究暂且不写。
Step2. 利用pandas.interpolate(inplace=True)进行线性插补缺漏值。
- Dataframe 行选择和列选择
参考了http://blog.csdn.net/u013045749/article/details/48370007 和 http://www.cnblogs.com/kylinlin/p/5231404.html
在不知道列名的情况下,用索引位置选择列,用df[[列索引]];
df.iloc[行索引],选取第X行,也可以用df.iloc[0:2]选取第0、1行,df[0:2]也是选取第0、1行。
对于新增一列用pandas的话:
令cframe['os'] == ‘Windows’
cframe.loc[cfeame['a'].str.contains('Windows'),'os'] = 'Windows'