Spark 数据分析 求助大神
现在我有一组数据,第一列是入站口到出站口(OD),第二列是刷卡的卡号,第三列是出行总时间。
现在我想研究在相同的OD下,出行时长的分布,并从中筛选出出行时长异常的卡号,默认出行时长超过该OD最短出行时长2倍为异常。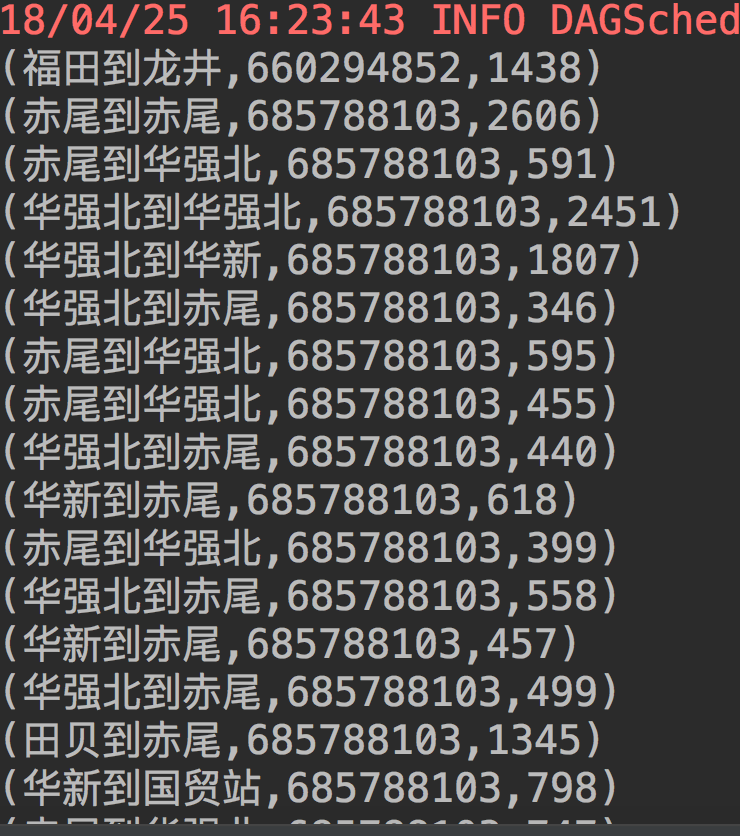
spark sql 分两步处理:
第一步:将文件映射成表1 求出每个OD的最短出行时长,结果注册为表2
第二步:表1和表2 join 筛选异常
现在我有一组数据,第一列是入站口到出站口(OD),第二列是刷卡的卡号,第三列是出行总时间。
现在我想研究在相同的OD下,出行时长的分布,并从中筛选出出行时长异常的卡号,默认出行时长超过该OD最短出行时长2倍为异常。
spark sql 分两步处理:
第一步:将文件映射成表1 求出每个OD的最短出行时长,结果注册为表2
第二步:表1和表2 join 筛选异常