求大神修改c++代码。统计一篇英文文章中所有单词出现次数。
题目要求:
要求统计一篇英文文章中的所有单词出现的次数,按照这些单词出现的顺序依次打印它们以及各自出现的次数。
本人已写出能实现统计的代码,但目前仍有一些无法解决:
1.如何不统计比如“word,”后面的“,”使之不被统计为“word,”而是“word”。
2.如何使如“word,and”不被统计为“word,and”而是当有“,”号时如我代码中空格进行跳过。正确被统计应该为“word”与“and”。
3.不只是“,”其他常用英文符号如“。”“!”“ ' ”“?”“...”等等做到如上要求。
4.求对修改的地方进行注释十分感谢!!!十分感谢求大神支援!!
代码:
#include <iostream>
#include <string.h>
#define X 1000
#define Y 45
using namespace std;
int main()
{
char str1[X][Y];
char str2[X];
int str3[X];
int i=0,j=0,k=0,t=0,x=0;
cout<<"请输入英文语句:"<<endl;
gets(str2);
t=strlen(str2)+1;
cout<<"---------------"<<endl<<"你输入的语句为:"<<endl<<"---------------"<<endl<<str2<<endl<<"---------------"<<endl;
while(j<t)
{
for(;str2[j]==32;j++);
while(k<Y&&str2[j]!=32)
str1[i][k++]=str2[j++];
str1[i][k]='\0';
str3[i]=1;
for(x=0;x<i;x++)
if(strncmp(str1[i],str1[x],Y)==0)
{
str3[x]++;
i--;
break;
}
i++;
k=0;
}
cout<<"统计结果为:"<<endl;
t=0;
for(;t<i;t++)
cout<<str1[t]<<"总共有 "<<str3[t]<<" 个"<<endl;
}
#include <iostream>
#include <cstring>
#include <cstdio>
#define X 1000
#define Y 45
using namespace std;
int main()
{
char str1[X][Y];
char str2[X];
int str3[X];
int i=0,j=0,k=0,t=0,x=0;
cout<<"请输入英文语句:"<<endl;
gets(str2);
#这里不知道为什么要+1,去掉了
t=strlen(str2);
cout<<"---------------"<<endl<<"你输入的语句为:"<<endl<<"---------------"<<endl<<str2<<endl<<"---------------"<<endl;
while(j<t)
{
for(;str2[j]==32;j++);
while(k<Y&&str2[j]!=32&&str2[j]!='\0')
#不明白单词具体要求,这里写的是假设当前不是字母就不算在单词里,如果单词中间可能出现其他字符,再加上对str2[j+1]的判断,或者判断是否是某些特殊字符如逗号等
if (('a' <= str2[j] && str2[j] <= 'z') || ('A' <= str2[j] && str2[j] <= 'Z'))
str1[i][k++]=str2[j++];
else
j++;
str1[i][k]='\0';
str3[i]=1;
for(x=0;x<i;x++)
if(strncmp(str1[i],str1[x],Y)==0)
{
str3[x]++;
i--;
break;
}
i++;
k=0;
}
cout<<"统计结果为:"<<endl;
t=0;
for(;t<i;t++)
cout<<str1[t]<<"总共有 "<<str3[t]<<" 个"<<endl;
}
#include <iostream>
#include <cstring>
#include <stdio.h>
using namespace std;
int main()
{
char str[1000];
int i=0;
while((str[i]=getchar())!='\n')
{
i++;
}
str[i]='\0';
int num=0,n1[100],n2[100];
string stri1[100]= {""},stri2[100];
n1[0]=-1;
for(i = 0; str[i]!='\0'; i++)
{
if(str[i] == ' ')
{
num++;
n1[num]=i;
}
}
num++;
n1[num]=i;
cout<<"共有"<<num<<"个单词"<<endl;
for(i=0; i<num; i++)
{
for(int m=n1[i]+1; m<n1[i+1]; m++)
stri1[i]+=str[m];
}
int m=0;
bool f=true;
for(i=0; i<num; i++)
{
for(int l=0; l<m; l++)
{
if(stri2[l]==stri1[i])
{
f=false;
break;
}
else
{
f=true;
}
}
if(f)
{
stri2[m++]=stri1[i];
}
}
for(i=0; i<m; i++)
{
int l=0;
for(int n=0; n<num; n++)
if(stri2[i]==stri1[n])
l++;
n2[i]=l;
}
int sum=0;
for(i=0; i<m; i++)
{
cout<<stri2[i]<<' '<<n2[i]<<endl;
sum+=n2[i];
}
return 0;
}
#include
#include
#define X 1000
#define Y 45
using namespace std;
int main()
{
char str1[X][Y];
char str2[X];
int str3[X];
int i=0,j=0,k=0,t=0,x=0;
cout<<"请输入英文语句:"<<endl;
gets(str2);
t=strlen(str2)+1;
cout<<"---------------"<<endl<<"你输入的语句为:"<<endl<<"---------------"<<endl<<str2<<endl<<"---------------"<<endl;
while(j<t)
{
for(;str2[j]<65||(str2[j]>90&&str2[j]<97)||str2[j]>122;j++);//跳过所有非英文字母
while(k<Y-1&&((str2[j]>64&&str2[j]<91)||(str2[j]>96&&str2[j]<123)))//接受英文字母
str1[i][k++]=str2[j++];
str1[i][k]='\0';
str3[i]=1;
for(x=0;x<i;x++)
if(strncmp(str1[i],str1[x],Y)==0)
{
str3[x]++;
i--;
break;
}
i++;
k=0;
}
cout<<"统计结果为:"<<endl;
t=0;
for(;t<i;t++)
cout<<str1[t]<<"总共有 "<<str3[t]<<" 个"<<endl;
}
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
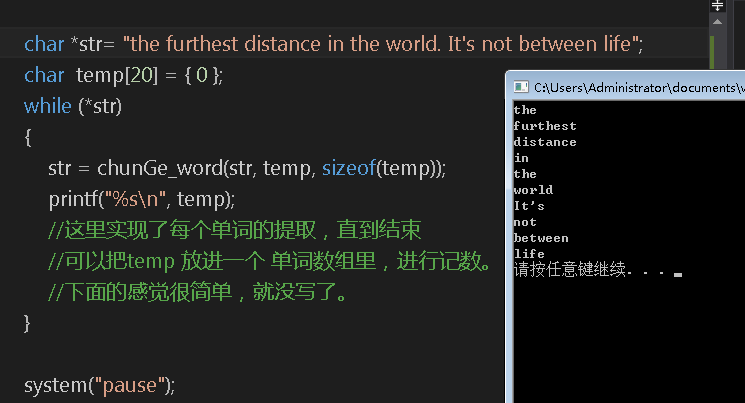
char * chunGe_word(char *str, char *temp,int temp_lenght)
{
/*
从str处开始,非字母跳过。遇到字母,作为每个单词的起点
直到遇到非字母时结束一个单词的提取。并返回结束位置。
如果这个单词太长,超过了temp 的容量 则超过的丢弃。
找不到匹配的单词,就返回NULL;
思路:利用两个辅助指针来挖单词。一个指向头部 一个指向尾部。他们的之间的就是单词
*/
if(str==NULL)
{
return str;
}
int i = 0;
char *buf = str;
char *star = NULL;//开始的位置标记
char *end = NULL;//结束的位置标记
while (*buf)
{
if (*buf >= 'A'&&*buf <= 'Z' || *buf >= 'a'&&*buf <= 'z')
{
star = buf;//找到单词开始处
break;
}
buf++;
}
while (*buf)
{
if (*(buf + 1) == 0)//处理到达尾部的情况。
{
end = buf+1;//指向结束的标志
break;
}
//这里多了一个 ‘!’表示不是字母就结束了单词的判断。
//但有很多例外 比如 It's '算单词的一部分啊
//还有一些特殊的情况,就不处理了。需要的时候在这里升级吧。
if (!(*buf >= 'A'&&*buf <= 'Z' || *buf >= 'a'&&*buf <= 'z' || *buf == 0x27/* ' =0x27 */))
{
end = buf;//这里单词结束。
break;
}
buf++;
}
int lenght = (int)(end - star);//单词长度。两个指针的差值
if (lenght> temp_lenght - 1)//如果超过容量
{
memcpy(temp,star, temp_lenght - 1);//留一个结束符
}
else
{
memcpy(temp,star, lenght);
temp[lenght] =0;//处理短与容器的值,防止数据污染。假设temp[4] 第一次放进去了“int”
//第二次放进去短的 “in” .则还会输出"int" 所以这里lenght+1 就应该结束了
//容器的刷新应该属于底层的活,不应该让上层业务去保证temp的正确性
}
return end;
}
int main()
{
char *str= "the furthest distance in the world Is not between life";
char temp[20] = { 0 };
while (*str)
{
str = chunGe_word(str, temp, sizeof(temp));
printf("%s\n", temp);
//这里实现了每个单词的提取,直到结束
//可以把temp 放进一个 单词数组里,进行记数。
//下面的感觉很简单,就没写了。
}
system("pause");
}