python爬虫编码问题 怎么都改不好
第一天学习爬虫就遇到了这个问题,在网上找了很多解决办法都解决不了,希望有人能帮忙解决一下,感谢!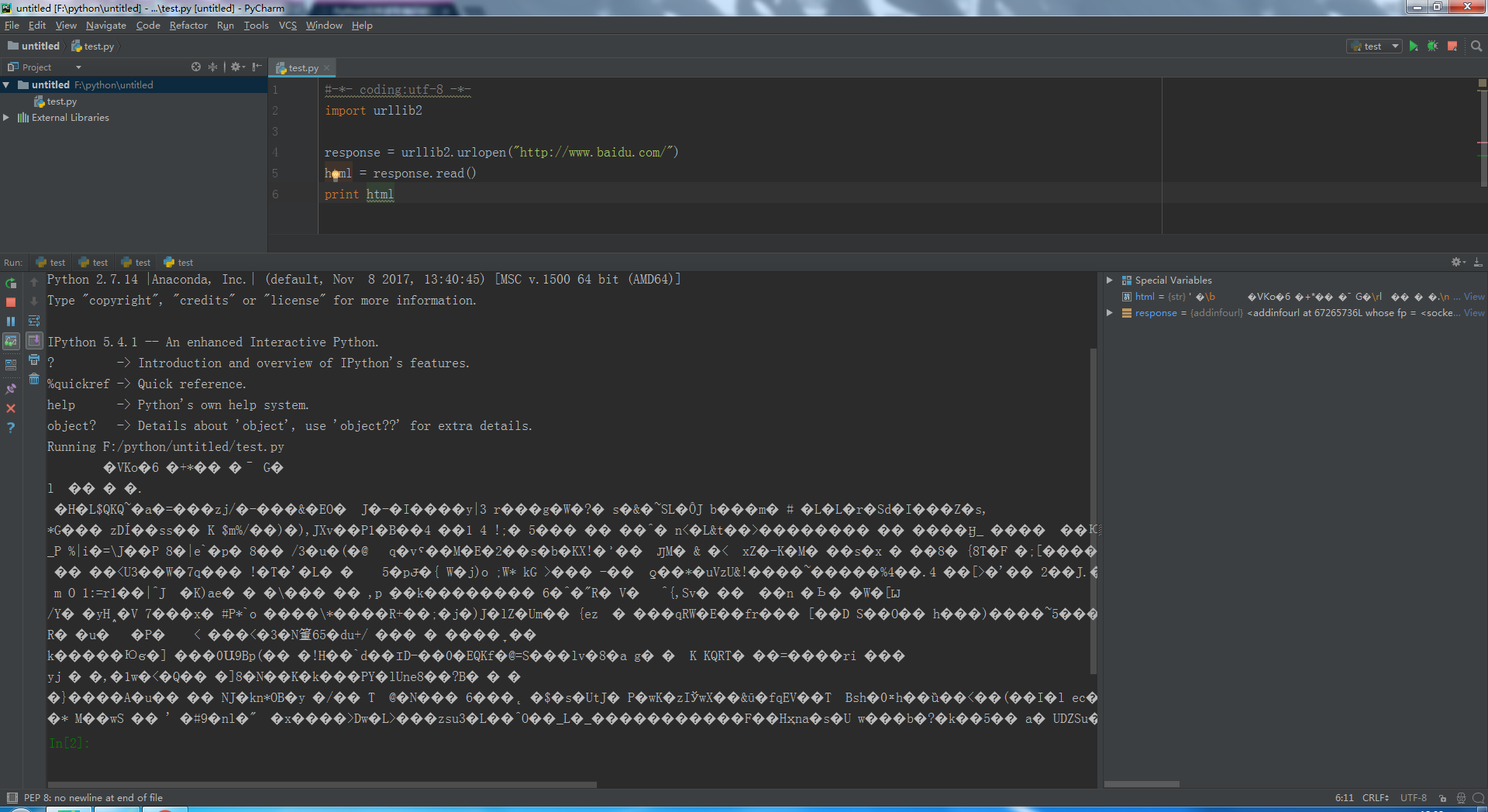
这明显是编码问题:你这样写 print html.decode('utf-8)
还是不行,
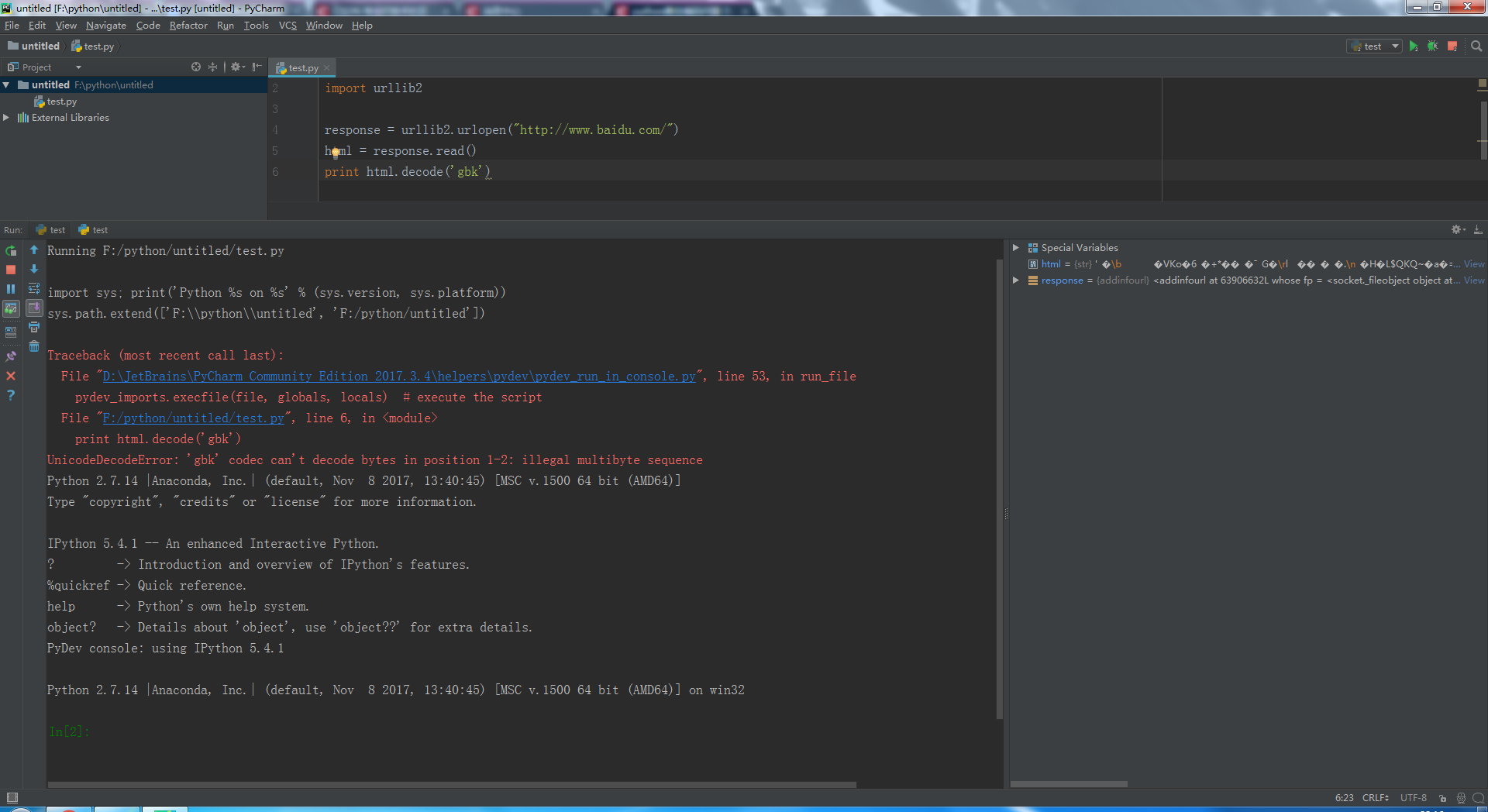
可以网上找找第三方的自动检测编码的库。或者把网页在浏览器打开,查查是什么编码。
encode('utf-8')
我自己写了一个,Python3.5的代码:
#coding=utf-8
#网页爬虫
from urllib import parse,request
header_dict = {
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Language":"zh-CN,zh;q=0.9",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
def get_http(load_url,has_header):
res=""
try:
req=None
if has_header:
req = request.Request(url=load_url,headers=header_dict)
else :
req = request.Request(url=load_url)
resu = request.urlopen(req)
resu = resu.read()
#print(res)
#输出内容(python3默认获取到的是16进制'bytes'类型数据 Unicode编码,如果如需可读输出则需decode解码成对应编码):b'\xe7\x99\xbb\xe5\xbd\x95\xe6\x88\x90\xe5\x8a\x9f'
#print(res.decode(encoding='utf-8'))
res=resu.decode(encoding='utf-8')
except Exception as e:
print(e)
return res
res=get_http("http://www.baidu.com",True)
print(res)
#############################
#下面是部分输出:
var get = function(url) {
if(location.protocol === "http") {
return url;
}
var reg = /^(http[s]?:\/\/)?([^\/]+)(.*)/,
matches = url.match(reg);
/* 判断传入参数是域名还是地址,分别做处理 */
url = list.hasOwnProperty(matches[2])&&(list[matches[2]] + matches[3]) || url;
return url;
},
set = function(kdomain,vdomain) {
list[kdomain] = vdomain;
};
return {
get : get,
set : set
}
})();
</script>
<script>
//让用户更快看到首页
if(!location.hash.match(/[^a-zA-Z0-9]wd=/)){
document.getElementById("wrapper").style.display='block';
setTimeout(function(){
try{
编码检查问题:
1.使用pip安装chardet
python2.X:
pip install chardet
python3.X
pip3 install chardet
使用chadet判断
import chardet
chardet.detect(byte_str)
注意:参数是byte类型的数据,chardet是用来判断网页编码的。