python如何将带标签的特征向量直接导入到朴素贝叶斯分类器中进行分类
1 -0.251051 -0.098758 -0.334480 -0.802064 0.310410 0.369198
2 -0.114443 -0.252595 0.175786 -0.662360 0.241837 0.129143
3 -0.623884 0.200280 -0.043467 -0.078748 0.252802 0.539361
3 -0.115779 0.009689 -0.093336 -0.440753 0.016640 0.589645
2 -0.460982 -0.262591 0.250524 -0.556230 0.040779 0.373679
2 -0.161501 -0.208360 -0.406109 -0.761014 0.373958 0.391963
其中最前面的数字1 2 3为类别标签,后面为特征向量(只写出了六维,但是我真实数据有128维),我想把这些数据直接导入到朴素贝叶斯分类器中计算分类结果(准确率,召回,f1-score),(上面只是给的一小部分数据)。求一个能直接处理这些数据的python语言编写的朴素贝叶斯分类器,数据文件类型为txt。谢谢,非常感谢
数据文件是什么格式?txt csv??。。。
看你的描述,给出的数据应该是训练数据集。应该首先对训练数据集进行特征和标签分类。训练标签列记为Y_train,其余特征列记为X_train。对于朴素贝叶斯分类器,可以在scikit learn库中直接导入。把以上Y_train和X_train直接fit,然后对测试集进行预测。希望能有帮助
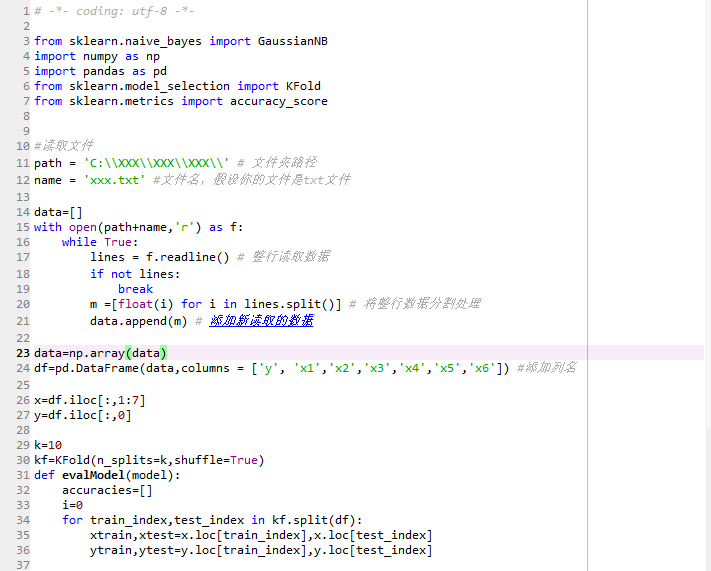
-*- coding: utf-8 -*-
from sklearn.naive_bayes import GaussianNB
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
#读取文件
path = 'C:\XXX\XXX\XXX\' # 文件夹路径
name = 'xxx.txt' #文件名,假设你的文件是txt文件
data=[]
with open(path+name,'r') as f:
while True:
lines = f.readline() # 整行读取数据
if not lines:
break
m =[float(i) for i in lines.split()] # 将整行数据分割处理
data.append(m) # 添加新读取的数据
data=np.array(data)
df=pd.DataFrame(data,columns = ['y', 'x1','x2','x3','x4','x5','x6']) #添加列名
x=df.iloc[:,1:7]
y=df.iloc[:,0]
k=10
kf=KFold(n_splits=k,shuffle=True)
def evalModel(model):
accuracies=[]
i=0
for train_index,test_index in kf.split(df):
xtrain,xtest=x.loc[train_index],x.loc[test_index]
ytrain,ytest=y.loc[train_index],y.loc[test_index]
model.fit(xtrain,ytrain)
y_pre=model.predict(xtest)
accuracy=accuracy_score(y_pred=y_pre,y_true=ytest)
accuracies.append(accuracy)
i+=1
print('GaussianNB 第{}轮:{}'.format(i,accuracy))
print('准确率为:',np.mean(accuracies),'\n')
model=GaussianNB()
evalModel(model)