利用sed和awk将列数据通过关键字转换为多列
将数据
4 00000080AB34
5 00000080AB35
5 00000080AB36
6 00000080AB37
4 00000080AB3A
180
?
9 00000080AA0C
10 00000080AA0E
4 00000080AA0F
1 00000080AA10
5 00000080AA12
194
?
9 00000080AA0C
5 00000080AA0E
5 00000080AA0F
7 00000080AA10
2 00000080AA12
200
?
转变为
4 00000080AB34 9 00000080AA0C 9 00000080AA0C
5 00000080AB35 10 00000080AA0E 5 00000080AA0E
5 00000080AB36 4 00000080AA0F 5 00000080AA0F
6 00000080AB37 1 00000080AA10 7 00000080AA10
4 00000080AB3A 5 00000080AA12 2 00000080AA12
180 194 200
? ? ?
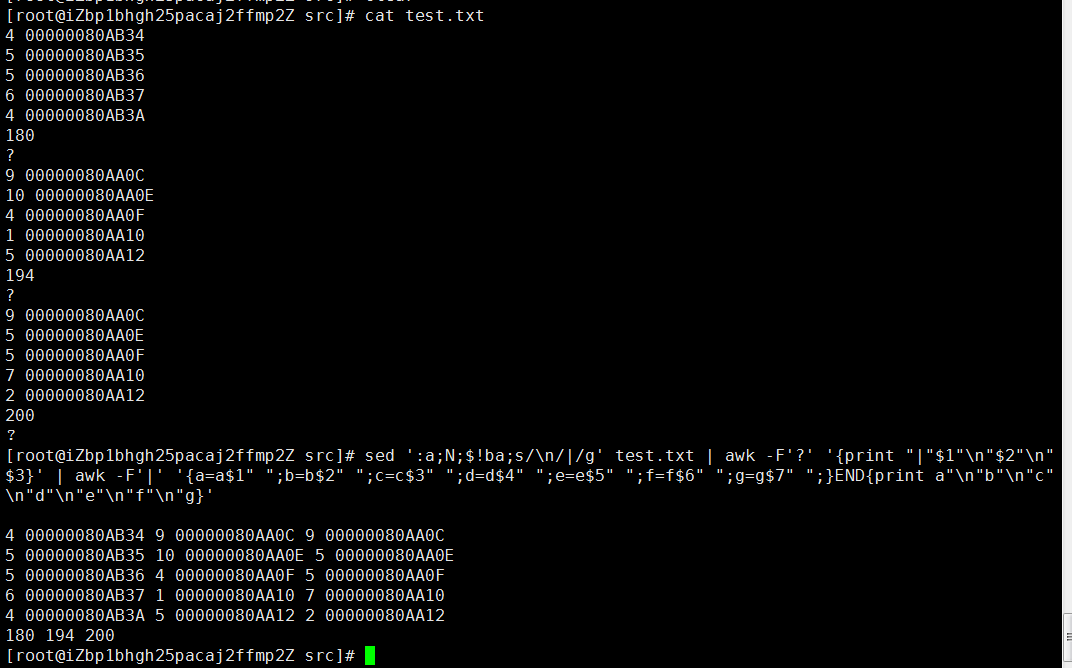
#shell命令:
#将每一个模块转成一行
sed ':a;N;$!ba;s/\n/|/g' test.txt | awk -F'?' '{print "|"$1"\n"$2"\n"$3}'
#将行和列位置互换,第一列赋给a,第二列赋给b,......
awk -F'|' '{a=a$1" ";b=b$2" ";c=c$3" ";d=d$4" ";e=e$5" ";f=f$6" ";g=g$7" ";}END{print a"\n"b"\n"c"\n"d"\n"e"\n"f"\n"g}' 文件名
#整合在一起
sed ':a;N;$!ba;s/\n/|/g' test.txt | awk -F'?' '{print "|"$1"\n"$2"\n"$3}' | awk -F'|' '{a=a$1" ";b=b$2" ";$3}' | awk -F'|' '{a=a$1" ";b=b$2" ";c=c$3" ";d=d$4" ";e=e$5" ";f=f$6" ";g=g$7" ";}END{print a"\n"b"\n"c"\n"d"\n"e"\n"f"\n"g}'
先把每个模块转成一行 sed 'sed ':a;N;$!ba;s/\n/|/g' text.txt | awk -F '?' '{for(i=1;i<=NF;i++){print $1}}”
然后就是awk 行转列了 awk -F '|' '{for(){...}end{for(){for{...}}}}'
大概是这个意思
sed 'sed ':a;N;$!ba;s/\n/|/g' text.txt | awk -F '?' '{for(i=1;i<=NF;i++){print $1}}”
awk -F "|" '{for(){...}end{for(){for{...}}}}'
我专门把这个写到博客上去了,里面有两种方法,你可以参考下:http://blog.csdn.net/m0_37886429/article/details/79034190