数据结构 关于二叉树的建立
public TreeNode create(char[] sequence,int index) {
TreeNode tempNode;
if(index>=sequence.length) {
return null;
}else {
tempNode=new TreeNode((int)sequence[index]);
tempNode.left_Node=create(sequence,2*index);
tempNode.right_Node=create(sequence, 2*index+1);
return tempNode;
}
}
如输入数组array={1,2,3,4,5,6,7,8}。root=create(array,1);
二叉树是怎么建立的?递归看的比较晕。。。。。
2i是左子树,2i+1是右子树
#include
#include
#include
#include
#include
#include
using namespace std;
#define QueueMaxSize 20 //定义队列数组长度
#define StackMaxSize 10 //定义栈数组长度
typedef char ElemType;
//二叉树结点
typedef struct BiTNode{
char data;
struct BiTNode lchild,*rchild;
}BiTNode,*BiTree;
//按先序序列创建二叉树
int CreateBiTree(BiTree &T){
char data;
//按先序次序输入二叉树中结点的值(一个字符),‘#’表示空树
scanf("%c",&data);
if(data == '#'){
T = NULL;
}
else{
T = (BiTree)malloc(sizeof(BiTNode));
//生成根结点
T->data = data;
//构造左子树
CreateBiTree(T->lchild);
//构造右子树
CreateBiTree(T->rchild);
}
return 0;
}
//输出
void Visit(BiTree T){
if(T->data != '#'){
printf("%c ",T->data);
}
}
//先序遍历
void PreOrder(BiTree T){
if(T != NULL){
//访问根节点
Visit(T);
//访问左子结点
PreOrder(T->lchild);
//访问右子结点
PreOrder(T->rchild);
}
}
//中序遍历
void InOrder(BiTree T){
if(T != NULL){
//访问左子结点
InOrder(T->lchild);
//访问根节点
Visit(T);
//访问右子结点
InOrder(T->rchild);
}
}
//后序遍历
void PostOrder(BiTree T){
if(T != NULL){
//访问左子结点
PostOrder(T->lchild);
//访问右子结点
PostOrder(T->rchild);
//访问根节点
Visit(T);
}
}
//中序非递归遍历
void InOrder2(struct BiTNode *T){
struct BiTNode p;
struct BiTNode* s[StackMaxSize]; //定义s数组作为存储根结点的指针的栈使用
int top = -1; //栈顶指针置为-1,表示空栈
p=T;
if(!p){
printf("空树");
return;
}
while(p||top!=-1){
while(p){
top++;
s[top]=p;
p=p->lchild;
}
p=s[top];
s[top]=NULL;
top--;
printf("%c ",p->data);
p=p->rchild;
}
}
int main()
{
printf("创建二叉树:\n");
BiTree T;
CreateBiTree(T);
printf("先序遍历:\n");
PreOrder(T);
printf("\n");
printf("中序遍历:\n");
InOrder(T);
printf("\n");
printf("中序遍历(非递归):\n");
InOrder2(T);
printf("\n");
printf("后序遍历:\n");
PostOrder(T);
printf("\n");
return 0;
}
if(index>=sequence.length) 表示这个节点不存在
因为 indexi是 数据域 在sequence数组中的下标
sequence [index] 就是即将创建的结点的数据域 如果index>数组长度 那么sequence [index]就为空 表示节点不存在 返回NULL;
所以 index < sequence.length 表示节点存在
然后 tempNode=new TreeNode((int)sequence[index]); 创建新节点
接着分别创建这个节点的左孩子和右孩子
tempNode.left _ Node=create(sequence,2 * index); tempNode.right _ Node=create(sequence,2 * index+1);
之所以创建左孩子传入的下标是 2 * index 右孩子传入的是,2 * index+1
是因为在顺序存储结构中 根节点存在数组下标为1的位置 即sequence [1]
若当前结点存在sequence [i] i,那么它的左孩子存在sequence [2 * i] ;右孩子存在sequence [2 * i+1] i+1;
tempNode.left_Node=create(sequence,2*index);//这里是创建左子树,2*index是左子树的根序号,然后创建完后会继续向下递归创建这个根的左子树
tempNode.right_Node=create(sequence, 2*index+1);//同理这个是创建右子树,2*index+1是右子树的根序号
总的这个递归就是创建一颗二叉树,先创建一个根的左子树(从开始看就是 1 是根)然后以2作为左子树的根,然后其实接下来会继续向下递归,就是以4为根的左子树,直到不能再创建左子树(2*index,不在数组中时)时return,然后执行创建那个根的右子树,然后继续进入递归又会创建那个右子树的左子树。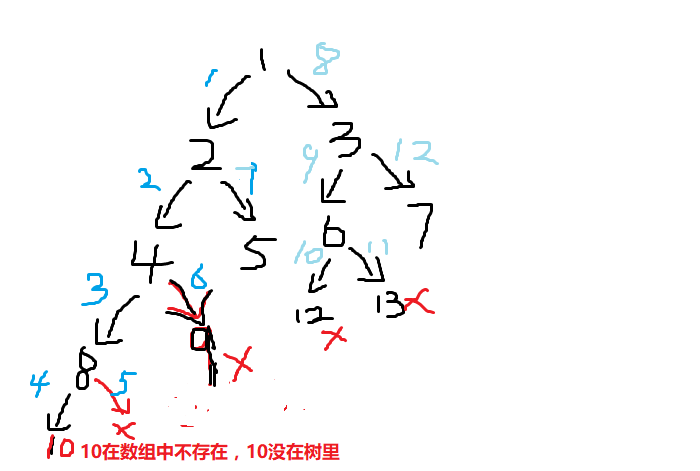
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
5,和7也是会像左子树和右子树向下递归的(虽然不会生成节点,数据在数组中没有),上面忘了画了
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
public static void main(String[] args) {
//生成1000个 0~2000的随机数
HashSet<Integer> hs= new HashSet();
while(hs.size()<1000){
int value=(int)(Math.random()*2000);
hs.add(value);
}
ArrayList<Integer> al= new ArrayList(hs);
//冒泡排序
boolean b= true;
while(b){
b=false;
for(int i=0;i<al.size()-1;i++){
if(al.get(i)>al.get(i+1)){
int num= al.get(i);
al.set(i, al.get(i+1));
al.set(i+1, num);
b=true;
}
}
}
for(int v:al){
System.out.println(v);
}
int des=888; //二分查找
int minIndex=0;
int maxIndex=999;
while(true){
//计算中间下标
int midIndex=(minIndex+maxIndex)/2;
//找到了
if(des==al.get(midIndex)){
System.out.println("所查询的数为: "+al.get(midIndex));
break;
}
//找到的值大
if(des<al.get(midIndex)){
maxIndex=midIndex-1;
}
//找到的值小
if(des>al.get(midIndex)){
minIndex=midIndex+1;
}
//没找到
if(minIndex>maxIndex){
System.out.println("没有生成这个数");
break;
}
}
}
二叉树建立要看你按那个遍历方式去存储
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
你多看课本照着葫芦画瓢,老师上课说的还不如课本。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
同上,水一波经验,2i是左子树,2i+1是右子树
上面这@qhlpptdyfn 兄弟的图很清楚了
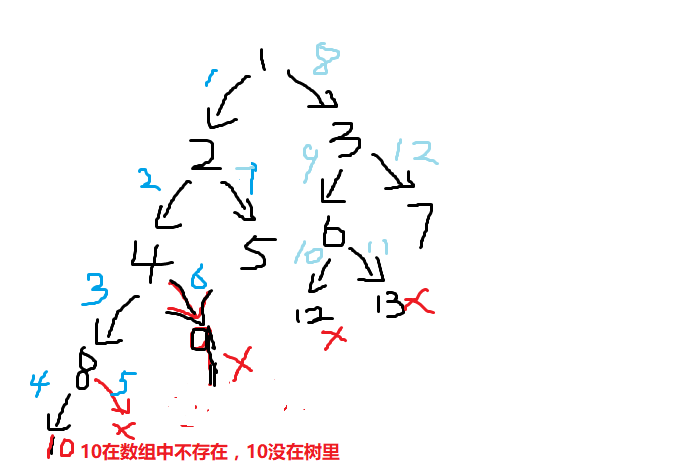
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
这个二叉树,我也很想问。
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
1、构造二叉树
Status InitTree(BiTree &T)
{
T = NULL;
return OK;
}
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
tempNode.right_Node=create(sequence, 2*index+1);//同理这个是创建右子树,2*index+1是右子树的根序号
总的这个递归就是创建一颗二叉树,先创建一个根的左子树(从开始看就是 1 是根)然后以2作为左子树的根,然后其实接下来会继续向下递归,就是以4为根的左子树,直到不能再创建左子树(2*index,不在数组中时)时return,然后执行创建那个根的右子树
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
数组的长度大于1的话,就分别创建左右子树,tempNode.left_Node=create(sequence,2*index);
//这句就创立了左子树,如果左子树的元素个数部位1再创建左子树的左右子树
同理,tempNode.right_Node=create(sequence, 2*index+1);
输入的顺序就是你的前序遍历顺序
就是不断递归
if(index>=sequence.length) 表示节点不存在
因为 indexi是 数据域 在sequence数组中的下标
sequence [index] 就是即将创建的结点的数据域 如果index>数组长度 那么sequence [index]就为空 表示节点不存在 返回NULL;
所以 index < sequence.length 表示节点存在
然后 tempNode=new TreeNode((int)sequence[index]); 创建新节点
接着分别创建这个节点的左孩子和右孩子
tempNode.left _ Node=create(sequence,2 * index); tempNode.right _ Node=create(sequence,2 * index+1);
之所以创建左孩子传入的下标是 2 * index 右孩子传入的是,2 * index+1
是因为在顺序存储结构中 根节点存在数组下标为1的位置 即sequence [1]
若当前结点存在sequence [i] i,那么它的左孩子存在sequence [2 * i] ;右孩子存在sequence [2 * i+1] i+1;
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。
二叉树的建立采用的是递归的思想:给定一个指向根节点的指针,然后递归调用ceate()函数,自动生成一个二叉树。就像是在地上挖了个坑(根节点),然后他会拿着铲子(create函数)按照一定的规则自动挖一个很大的洞穴(二叉树)出来。当然挖坑前需要先定义每个洞长什么样(定义节点结构)。
二叉树的遍历采用的也是递归的思想:如果节点有数据,则按照遍历规则打印根节点和孩子节点,没有数据则返回直到所有数据都遍历完,递归结束。