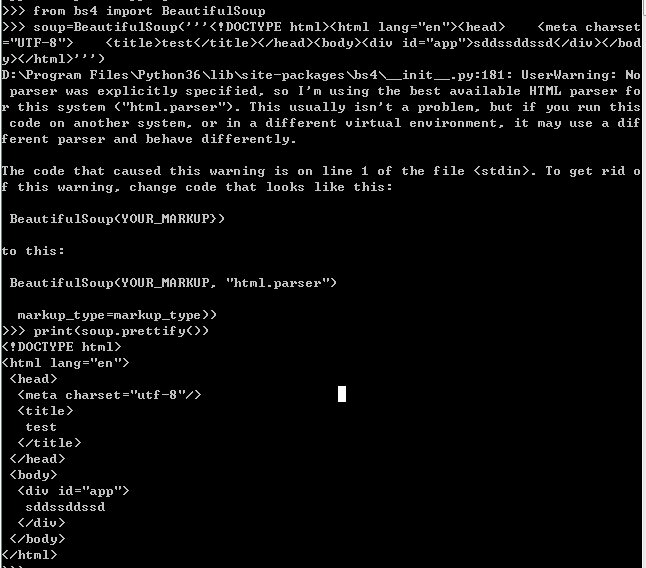
关于beautifulsoup4的初始化问题
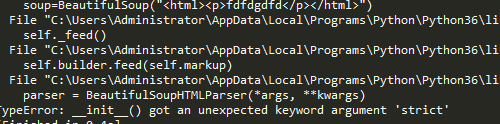
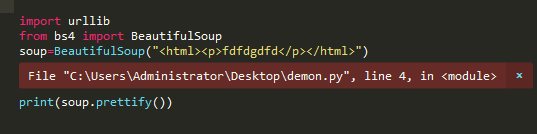
为什么照着别人教程打,会出现这种错误?
你的HTML不对,应该是HTML有问题,用下面这段HTML试试:
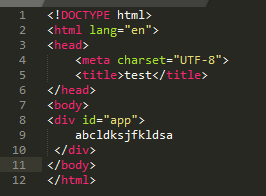
回复没法贴HTML,你按照图片试试。
给你串代码 自己领悟,当初写的爬虫百度新闻源码使用bs4的案例,
#coding:utf8
from bs4 import BeautifulSoup
import requests
url = 'http://news.baidu.com/'
web_data = requests.get(url)
web_data.encoding = 'utf-8'
soup = BeautifulSoup(web_data.content, 'lxml')
y = soup.find_all('div',id='pane-news')[0].find_all('ul')
new_dict={}
for news in y:
news_href=news.find_all('a')
for i in news_href:
new_dict[i.attrs['href']]=i.get_text().encode('utf-8')
for i in new_dict:
print i,new_dict[i]
你要不要吧写的BeautifulSoup中的html提出来
python
html = "<html><p>asdasdsad</p></html>"
这样你再试下
运行结果:
Python 3.6