爬微博自动翻页的问题
我现在在爬微博,然后页面时滑倒最下面才可以翻页,而且URL也没有变化。利用审查元素里的network抓到一个get请求,但是不知道怎么用,有人知道可以帮我解答一下吗,最好详细一点。Python 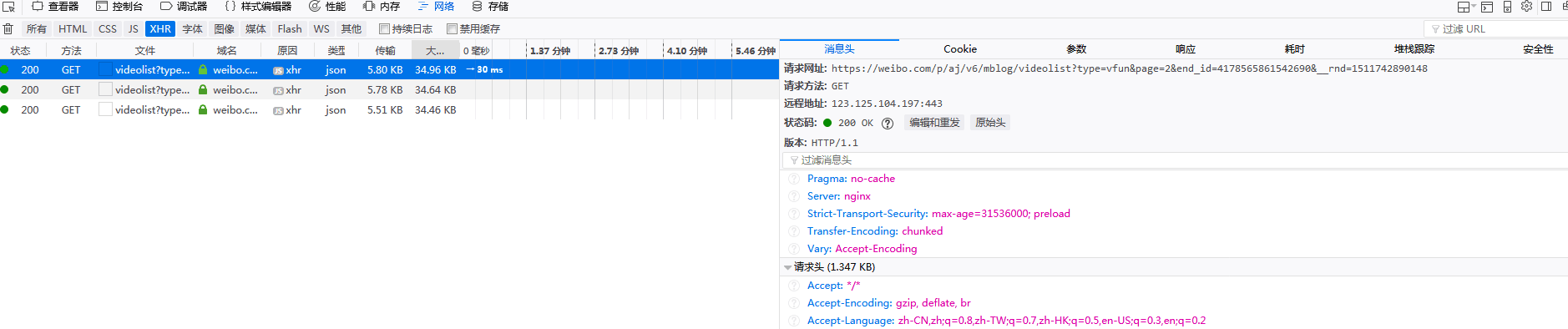
http://blog.csdn.net/monsion/article/details/7981366
动态爬虫的话我推荐使用selenium webdriver,只需要引用几个包,这东西可以模拟浏览器的操作,甚至可以渲染html、css、js,最近我也在尝试玩爬虫,特来推荐下。
URL没有变化,因为页面使用的是动态加载,请求是在ajax中发送到后台的,在network中可以捕获目标URL,把该URL作为目标URL反复请求,解析获取内容,一般该URL返回的是一个json串,分析其结构按需解析就是,需要注意的是,爬取微博数据最好设置一下请求头,模拟用户请求,如果还是抓取不到,可能就是服务器做了防抓取处理了,需要针对性分析(cookie),不过微博在百度搜索的权重还是比较高的,请求头可以设置百度蜘蛛的请求头
get参数变化,page=2为第二页,改变这个选项就可以
比较同意楼上的意见,一般都是page参数在变化。