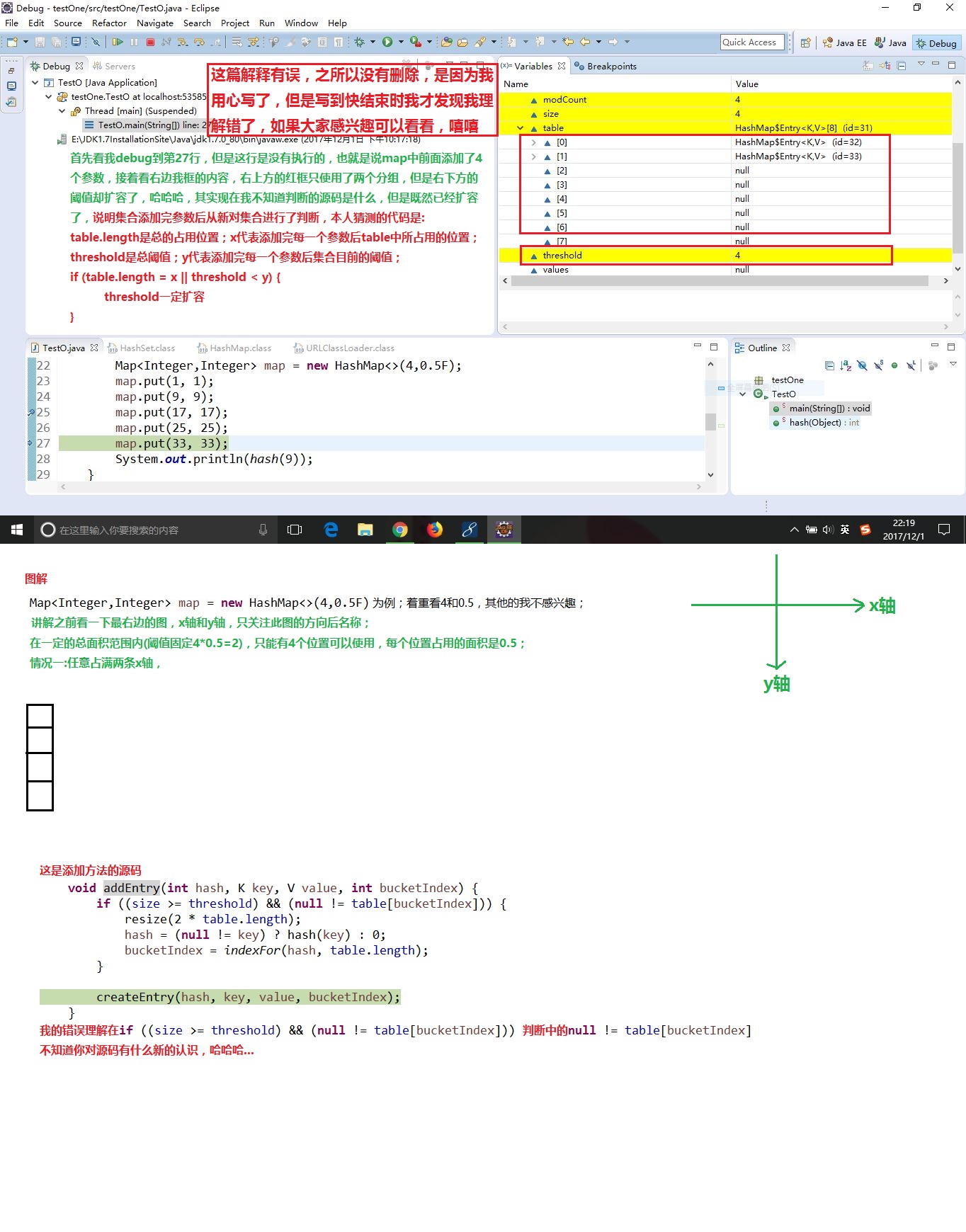
HashMap()中的分组组数与阈值之间的关系是什么?
我就直接上图了
我在详细的说一下我想问的问题点:
为什么我下面的代码执行完并没有扩容,但是允许的个数为2,现在我存了3个???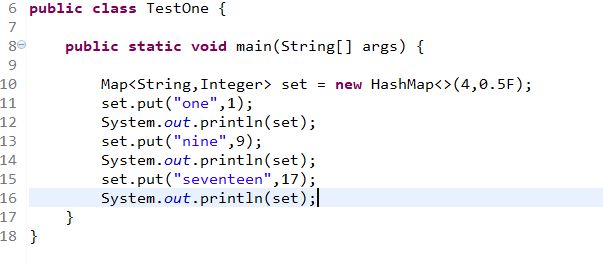
更正一下
null != table[bucketIndex]表示的是数组中hash值取余冲突的情况,也就是说,即使存放的数据数量超过threshold,但是如果存放位置是数组上的闲置位置(为null的位置),那么数组是不会扩容的(充分利用空间)
以下是修改后内容
看jdk1.7实现源码
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
indexFor方法是将hash值映射到你数组中的位置中(数组hash值与数组大小的&运算结果),再看addEntry方法
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
threshold是容量*加载因子,4*0.5=2,你存第三个确实满足了size >= threshold,但是不满足null != table[bucketIndex],也就是说你有两个key的hash值位运算之后存放在容量为4的数组中空闲位置里(如果下标在同一个位置(hash冲突),则同一个位置上数据以链表的形式纵向存储(假定在数组上的存储为横向存储)),所以没有扩容。至于有的人扩容了有的人没有扩容,那是因为存放的key不一样,所以hash值不一样,hash值不一样位运算结果就不一样,计算结果不一样存储在数组上的位置就不一样,只要存放的位置是闲置的,数组就不会扩容,但是这里有一个上限,当数组存满了,再继续存储便一定会产生冲突,从而扩容(一个优质的hash函数,应当避免散列后冲突的情况,我想当初设计者留下0.75的默认加载因子也应该是出于对hashmap的效率保护,避免过多的链表影响效率,在数组填满75%的空间下,hash冲突的几率应该是不大的)
以下是hash源码,以及获取数组下标源码
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
transient int hashSeed = 0;
int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
one,two,three没有扩容,但是one,two,three1扩容了,可以从debug看出
下面代码是从源码中提取出来的,用来获取字符串key在数组中的位置
public static void main(String[] args) {
System.out.println(indexFor(hash("one"),4));
System.out.println(indexFor(hash("two"),4));
System.out.println(indexFor(hash("three"),4));
System.out.println(indexFor(hash("three1"),4));
}
static final int hash(Object k) {
int h = 0;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
执行结果
3
1
0
3
three1跟one在数组中的存储位置冲突了,如果不扩容就会在one之后形成并列的链表形式存储,这样会大大影响Hash查询效率
结合之前我的分析,应该不难看出hashmap的扩容机理
当桶的数量不变,然后元素越来越多的时候,就会发生很多的hash冲突,所以达到一个阈值,就会重新对桶的数量进行扩容
阈值= 容量*加载因子
你说的分组组数就是容量吧
https://www.cnblogs.com/KingIceMou/p/6976574.html
ranxiyu11 请看如下图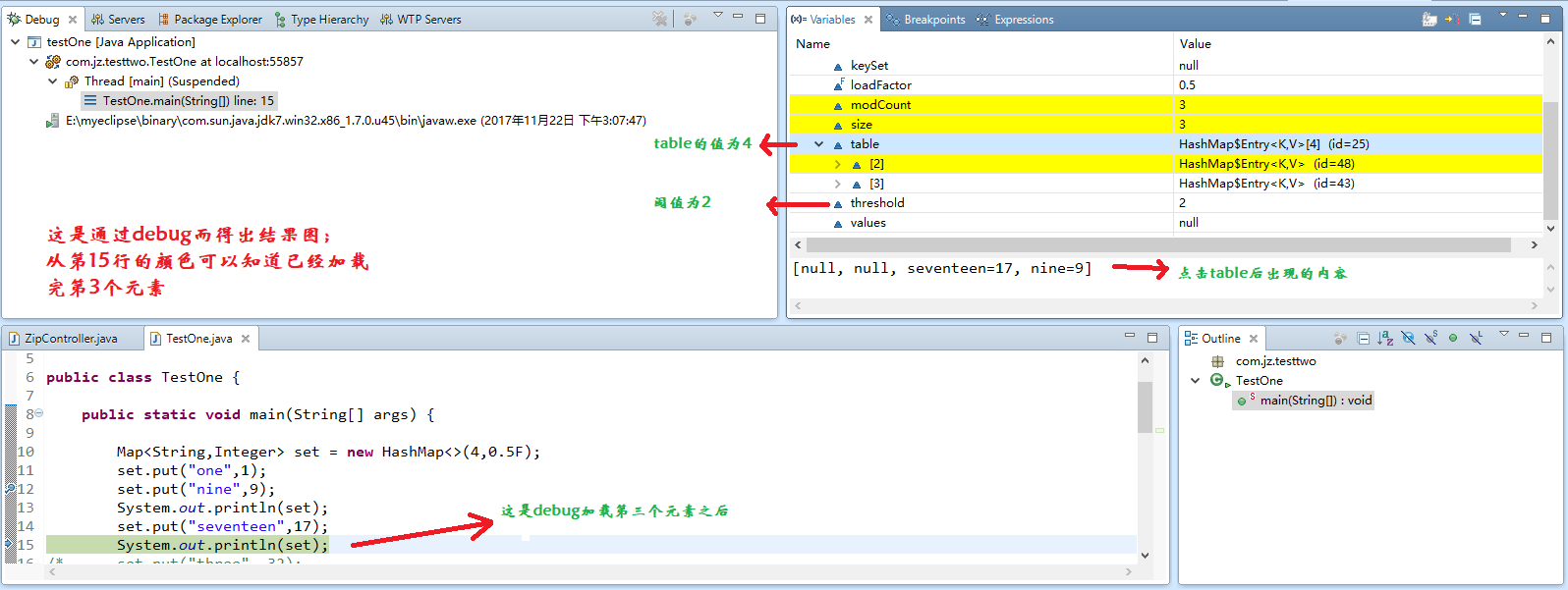
看jdk1.7实现源码
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
indexFor方法是将hash值映射到你数组中的位置中,可以简单理解为求余操作,再看addEntry方法
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
threshold是容量*加载因子,4*0.5=2,你存第三个确实满足了size >= threshold,但是不满足null != table[bucketIndex],也就是说你有两个key的hash值取余之后存放在容量为4的数组中同一个下标里,同一个位置是以以链表的形式存储,所以没有扩容,其实你在存放第三个元素的时候,数组只是用了两个位置而已,至于有的人扩容了有的人没有扩容,那是因为存放的key不一样,所以hash值不一样,hash值不一样取余获得的位置就不一样,只要存放的位置不重叠,map是一定会扩容的
这是一篇错误理解,大家可以看看