请求大神解答下如何用python读取复杂dat中文本文的问题
我会使用open('XXX').read()将本文中的数据全部读出来,但是在文本中存在着不同的列名,例如图片中的数据。请问大神何如用python将这些数据按照“id”,“url”,“brand”等类别进行输出划分,python不怎么会用,还请各位大神不吝赐教
http://blog.csdn.net/y394996630/article/details/48024833
这很明显是字典型的,infodict={"_id":"A00000"} 直接infodict["id"] 即可获得“A00000”
可以使用pandas来把字典转为DataFrame,然后就可以看到像表格一样的数据了,我只提供了一些思路哈,仅供参考
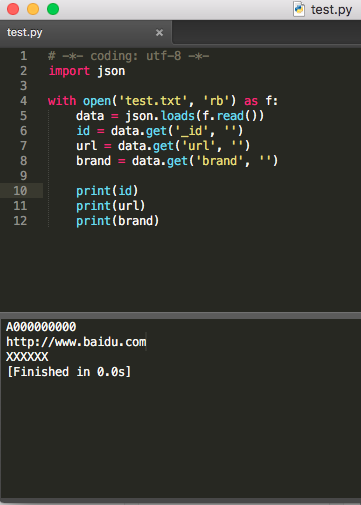
# -*- coding: utf-8 -*-
import json
with open('test.txt', 'rb') as f:
data = json.loads(f.read())
id = data.get('_id', '')
url = data.get('url', '')
brand = data.get('brand', '')
print(id)
print(url)
print(brand)
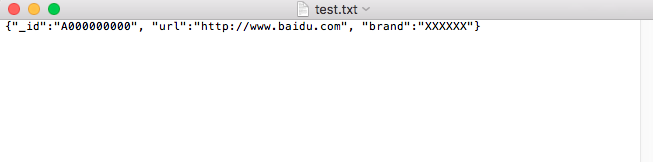
源文件如下:
测试结果如下: