SQL语句编写求助,两张表联合查询
有两张表如图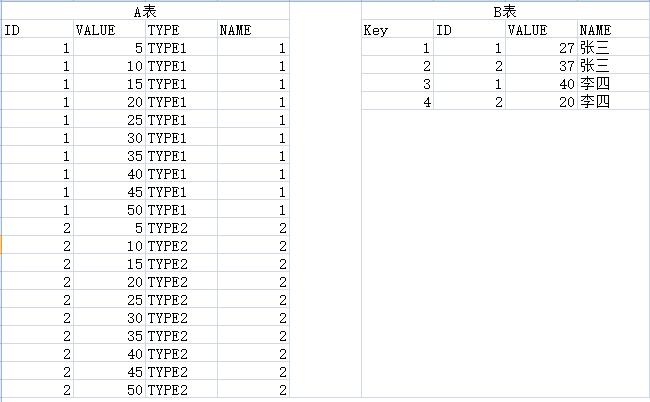
想根据B.Name in ('张三','李四') 来获取 8条数据
如图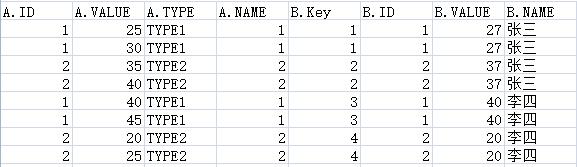
A表复合主键 ID+Vaule
B表主键Name
A.ID=B.ID
简单说来就是 取出B表同一个ID下 小于Value 的最大数据 和大于Value的最小数据
当B.Value处于 0或者max的时候只取出 一条(满足条件)即可
不限制 sql或者存储过程...
只需得到结果
这个问题我已经思考很久了, 并非一点sql 都不会 万望回答的朋友三思
---------------------------------------------------------分割线 以下内容为测试用建表sql以及数据
CREATE TABLE B(
[Name] nvarchar NOT NULL,
[ID] [int] NOT NULL,
[Value] [int] NOT NULL ,
[KEY] [int] NULL,
CONSTRAINT [PK_BAS_B] PRIMARY KEY CLUSTERED
(
[Name] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('张三' ,1 ,27 ,1)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('张三' ,2 ,37 ,2)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('李四' ,1 ,20 ,3)
INSERT INTO B ([Name] ,[ID] ,[Value] ,[KEY]) VALUES('李四' ,2 ,40 ,4)
CREATE TABLE A(
[ID] [int] NOT NULL,
[Value] [int] NOT NULL ,
[TYPE] [int] NULL,
[NAME] nvarchar NULL,
CONSTRAINT [PK_BAS_A] PRIMARY KEY CLUSTERED
(
[ID] ASC,
[Value] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,5,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,10,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,15,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,20,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,25,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,30,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,35,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,40,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,45,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (1,50,1,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,5,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,10,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,15,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,20,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,25,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,30,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,35,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,40,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,45,2,'test')
INSERT INTO A([ID],[Value],[TYPE],[NAME]) VALUES (2,50,2,'test')
刚开始之时很好奇,为什么楼主要用100C来写一个sql语句?很不明白
结果就抱着一试的态度,开始弄一下,结果就开始跟这个sql语句较劲了,我还就不信我弄不出来,这将是我写的最长的sql语句啊
花了我一个多小时,看来我的mysql功底还不行啊
1.首先根据楼主的数据库,我进行提取了关键字段,然后在本地数据库进行建表,表的结构和数据如下
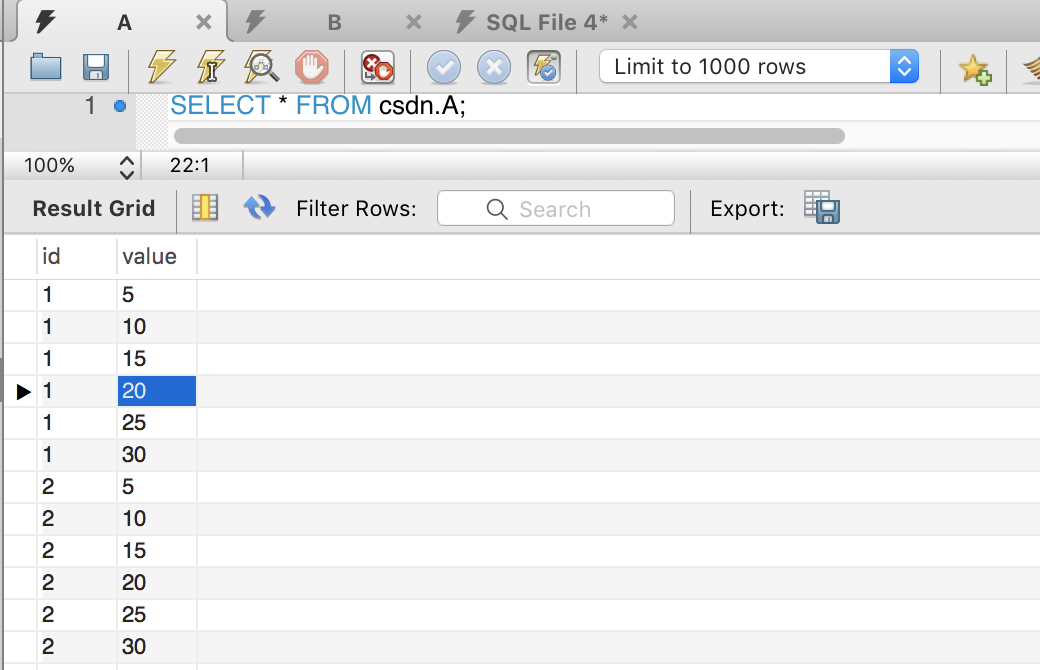
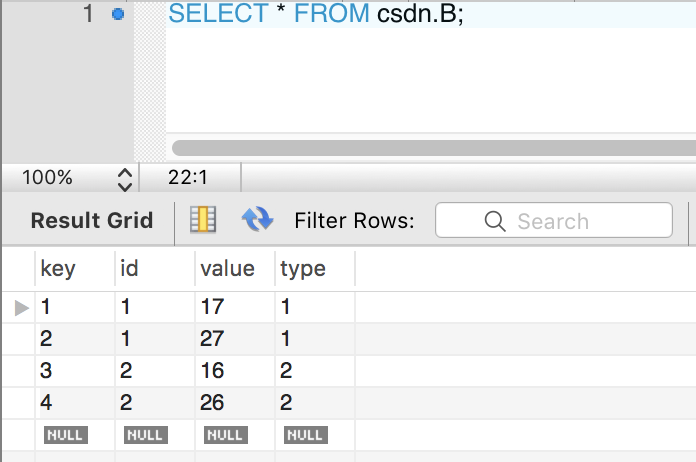
2.sql语句
SELECT
A.id, A.value, B.key, B.id, B.value, B.type
FROM
csdn.B B
LEFT JOIN
csdn.A A ON A.id = B.id
# 对A中value和B中的value进行塞选
# 这里需要有来两个条件来确定一条数据
# 首先获取到根据B中value确定一个A中最大值中的最小值
# 如果这时候单纯只根据这一个value将会有两条数据,本来应该只有一条的,因为单纯只根据 A.id = B.id和A.value = ? 存在两条数据符合
# 这时候我们应该在根据B.value来确定这个 这就是为什么 in 前面有(A.value , B.value)
AND (
# --根据B.value小于A中的value的最小值-- start.....
(A.value , B.value) IN ((SELECT
MIN(valueA), valueB
FROM
# 根据B.value小于A中的value来获取所有的A中的列
(SELECT
A.value valueA, B.value valueB
FROM
csdn.A A, csdn.B B
WHERE
B.type IN (1 , 2) AND A.id = B.id
AND A.value > B.value) gro
# 根据 valueB分组并获取最小的A.value
GROUP BY valueB))
# --根据B.value小于A中的value的最小值-- end.....
# 根据B.value大于A中的value的最大值,和上面的情况一样
OR (A.value , B.value) IN ((SELECT
MAX(valueA), valueB
FROM
(SELECT
A.value valueA, B.value valueB
FROM
csdn.A A, csdn.B B
WHERE
B.type IN (1 , 2) AND A.id = B.id
AND A.value < B.value) gro
GROUP BY valueB)))
亲测,是正确的,截图如下
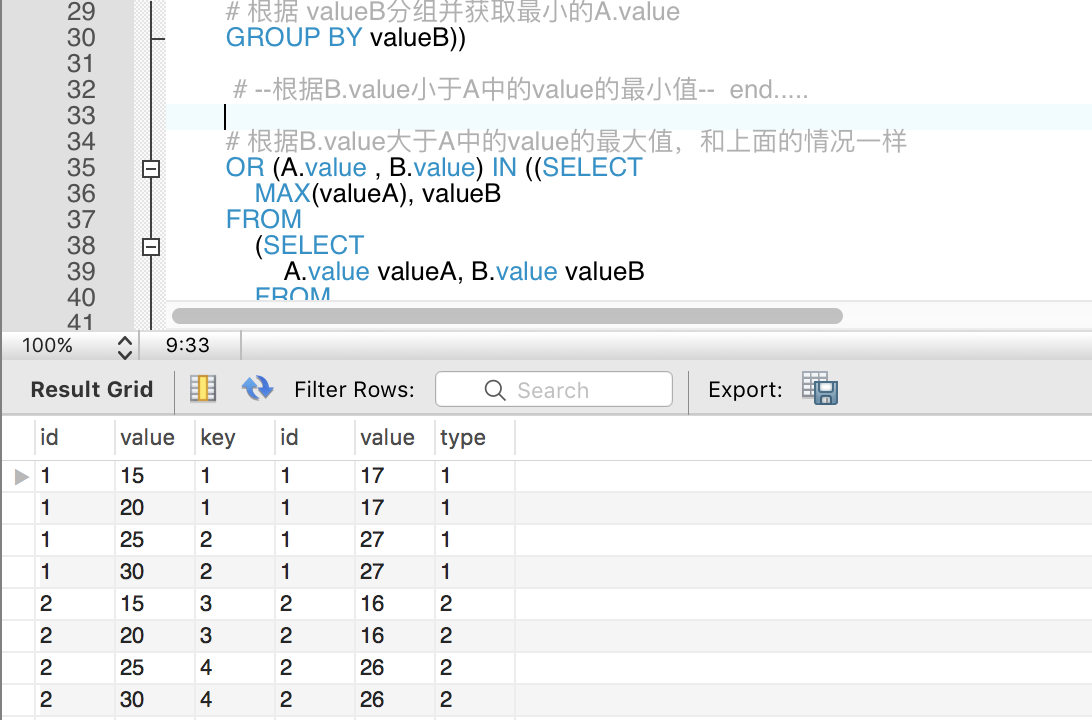
select * from a left join b on a.id=b.aid
不考虑性能的情况下可以这样做,我这里提供一个思路
select A.ID,A.VALUE,A.TYPE,A.NAME,B.KEY,B.ID,B.VALUE,B.NAME
min(VALUE),max(VALUE) from A left join B on A.ID = B.ID
where B.NAME="你输入的名字"
and B.VALUE > (select min(VALUE) from B where NAME="你输入的名字"))
and B.VALUE < (select min(VALUE) from B where NAME="你输入的名字"));
希望能帮到您
最后面的min改成max cv大法走火入魔了
select A.ID,A.VALUE,A.TYPE,A.NAME,B.KEY,B.ID,B.VALUE,B.NAME
min(VALUE),max(VALUE) from A left join B on A.ID = B.ID
where B.NAME="你输入的名字"
或者
select A.ID,A.VALUE,A.TYPE,A.NAME,B.KEY,B.ID,B.VALUE,B.NAME
min(VALUE),max(VALUE) from A left join B on A.ID = B.ID
where A.ID=''
select a.id,b.VALUE,a.type,a.name,b.key,b.id,b.value,b.name
from tb_a a
left join tb_b b
on a.id = b.id
where abs(a.value-b.value) in (
select min(abs(a.value-b.value)) tn
from tb_a a
left join tb_b b
on a.id = b.id
group by b.VALUE, b.NAME)
补一张图
