python使用urllib2 批量下载文件,遇到校验怎么办?
已经获取了文件下载地址,下载之后总是1kb。
后来添加了cookie和reference,但没有解决问题。
抓包后发现,cookie一直在变化。
截图里的链接不需要校验,直接就能打开的,可能是你要下载的文件网页中没有(或者文件类型不对)
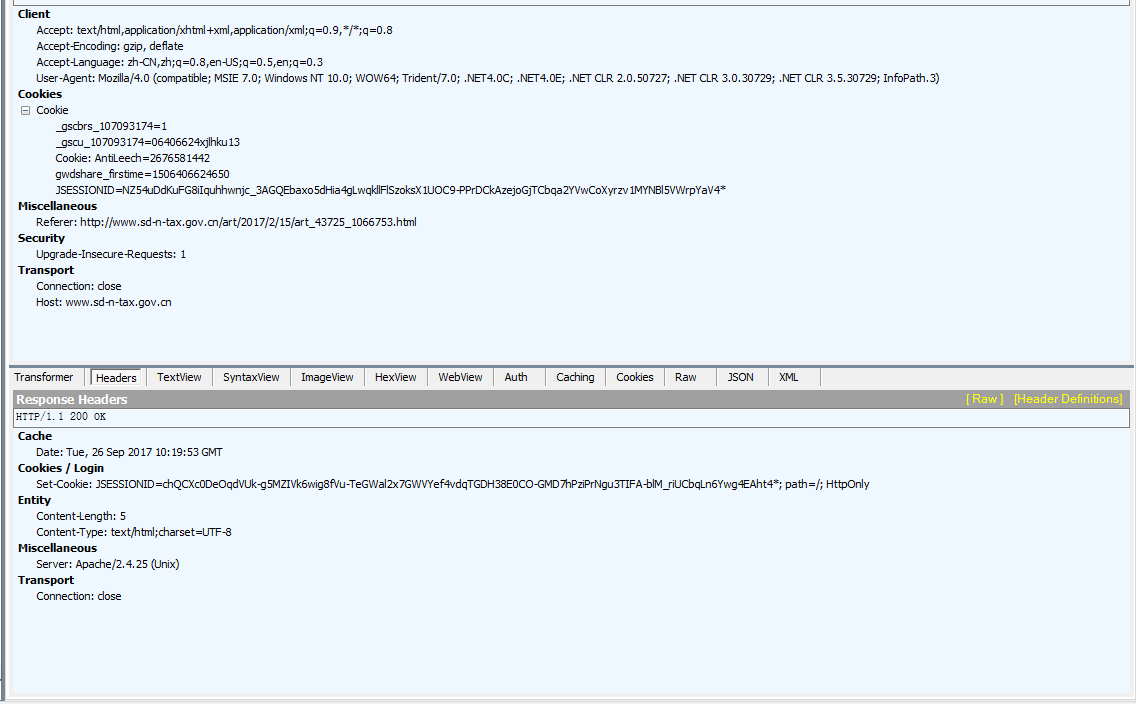
那就是服务器有反爬虫策略,发现你的程序是爬虫,你需要优化来让你的程序不被认为是爬虫
1、用requests 的自动session 管理
2、降低抓取速度
3、用代理去抓取
问题已解决,是网页下载的url被自动添加了多余的字符串,没有注意到