用python和tensorflow构建神经网络学习XOR函数
构建2层来学习XOR函数,但是学习结果无论调试多少次一直都无法学习到正确结果。
import tensorflow as tf
import numpy as np
def add_layer(inputs,in_size,out_size,activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size])) + 0.1
#biases=tf.constant(0.1,dtype='float32')
Wx_plus_b = tf.matmul(inputs,Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs,Weights,biases
X=np.array([[0,0],[1,0],[0,1],[1,1]],dtype=np.float32)
Y=np.array([[0,],[1,],[1,],[0,]],dtype=np.float32)
prediction1,w1,b1=add_layer(X,2,2,activation_function=tf.nn.relu)
prediction2,w2,b2=add_layer(prediction1,2,1,activation_function=tf.nn.sigmoid)
loss=tf.reduce_mean(tf.reduce_sum(tf.square(prediction2-Y),axis=1))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
sess.run(train_step)
#print(sess.run(tf.nn.sigmoid(tf.matmul(tf.matmul(X,sess.run(w1))+b1,w2)+b2)))
print(sess.run(prediction2))
以下是我的输出结果,与[0,1,1,0]相差甚远!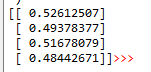
http://blog.csdn.net/u012560212/article/details/72957913
虽然问题过去了很久,回复一下也给以后的人看。
输出结果不对的原因有两个
1. 使用了一层隐含层,相当于感知器,感知器是不能划分xor的,需要加多一层隐含层
2. 偏置项b设置的太大,训练次数设置的太小的原因,影响了模型的收敛,把偏置项设置为加0.01或者直接不加也就是0,然后训练次数改为10000,得出结果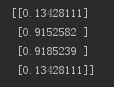
优化的话其实可以把relu删掉,没用,两层sigmoid隐含层就够了,loss function改为用mse均方误差,然后tensorflow的使用方面可以改为用新的写法,这样更方便看