SQL语句优化问题 执行速度太慢 ,如何优化
需要执行一段sql语句 但是效率 太低 能不能有办法 优化 子查询 太多了
SELECT ROWNUM RANKING, RES.*
FROM (SELECT STEPMEDAL.USER_ID,
SUM(STEPMEDAL.MEDALS) MEDALS,
REALNAME,
USER_IMG,
START_DATE,
END_DATE,
NVL(TOTAL.TOTAL_STEP_NUM, 0) TOTAL_STEP_NUM
FROM (SELECT INFO.USER_ID,
REALNAME,
START_DATE,
END_DATE,
USER_IMG,
NVL(MEDALS, 0) MEDALS
FROM (SELECT USERINFO.USER_ID,
EXT.REALNAME,
NVL(EXT.USER_IMG,0) USER_IMG,
TO_CHAR(ACTI.START_DATE, 'YYYY-MM-DD') START_DATE,
TO_CHAR(ACTI.END_DATE, 'YYYY-MM-DD') END_DATE
FROM JC_USER_EXT EXT,
JC_USER USERINFO,
JC_USER USERDEPART,
WALK_ACTIVITY_MAIN ACTI,
WALK_ACTIVITY_COMPANY_REL REL,
WALK_ACTIVITY_COMPANY_REL WACOM
WHERE USERDEPART.USER_ID = 12519
AND REL.COMPANY_ID = USERDEPART.DEPART_ID
AND WACOM.WA_ID = REL.WA_ID
AND USERINFO.DEPART_ID = WACOM.COMPANY_ID
AND EXT.USER_ID = USERINFO.USER_ID
AND ACTI.STATE = 1
AND ACTI.STATUS = 1
AND EXT.JOB_TYPE = 1
AND ACTI.WA_ID = WACOM.WA_ID) INFO
LEFT OUTER JOIN (SELECT USERINFO.USER_ID,
CASE
WHEN AVG(STEP.STEP_NUM) > 1800 THEN
1
ELSE
0
END MEDALS
FROM JC_USER USERINFO
LEFT OUTER JOIN WALK_USER_STEP STEP
ON USERINFO.USER_ID =
STEP.USER_ID, JC_USER
USERDEPART,
WALK_ACTIVITY_MAIN ACTI,
WALK_ACTIVITY_COMPANY_REL REL,
WALK_USER_STEP STEPDATE,
WALK_ACTIVITY_COMPANY_REL
WACOM
WHERE USERDEPART.USER_ID = 12519
AND REL.COMPANY_ID =
USERDEPART.DEPART_ID
AND WACOM.WA_ID = REL.WA_ID
AND USERINFO.DEPART_ID =
WACOM.COMPANY_ID
AND ACTI.STATE = 1
AND ACTI.STATUS = 1
AND ACTI.WA_ID = WACOM.WA_ID
AND STEP.STEP_ID =
STEPDATE.STEP_ID
AND TO_CHAR(STEPDATE.STEP_DATE,
'YYYY/MM') <>
TO_CHAR(SYSDATE, 'YYYY/MM')
AND STEPDATE.STEP_DATE BETWEEN
ACTI.START_DATE AND
ACTI.END_DATE
GROUP BY USERINFO.USER_ID,
TO_CHAR(STEPDATE.STEP_DATE,
'YYYY/MM')) STEPRES
ON INFO.USER_ID = STEPRES.USER_ID) STEPMEDAL
LEFT OUTER JOIN (SELECT STEPDATE.USER_ID,
SUM(STEPDATE.STEP_NUM) TOTAL_STEP_NUM
FROM JC_USER USERINFO
LEFT OUTER JOIN WALK_USER_STEP STEP
ON USERINFO.USER_ID = STEP.USER_ID,
JC_USER USERDEPART,
WALK_ACTIVITY_MAIN ACTI,
WALK_ACTIVITY_COMPANY_REL REL,
WALK_USER_STEP STEPDATE,
WALK_ACTIVITY_COMPANY_REL WACOM
WHERE USERDEPART.USER_ID = 12519
AND REL.COMPANY_ID =
USERDEPART.DEPART_ID
AND ACTI.WA_ID = WACOM.WA_ID
AND WACOM.WA_ID = REL.WA_ID
AND USERINFO.DEPART_ID =
WACOM.COMPANY_ID
AND ACTI.STATE = 1
AND ACTI.STATUS = 1
AND STEP.STEP_ID = STEPDATE.STEP_ID
AND STEPDATE.STEP_DATE BETWEEN
ACTI.START_DATE AND ACTI.END_DATE
GROUP BY STEPDATE.USER_ID) TOTAL
ON STEPMEDAL.USER_ID = TOTAL.USER_ID
GROUP BY STEPMEDAL.USER_ID,
REALNAME,
USER_IMG,
START_DATE,
END_DATE,
TOTAL.TOTAL_STEP_NUM
ORDER BY TOTAL_STEP_NUM DESC) RES
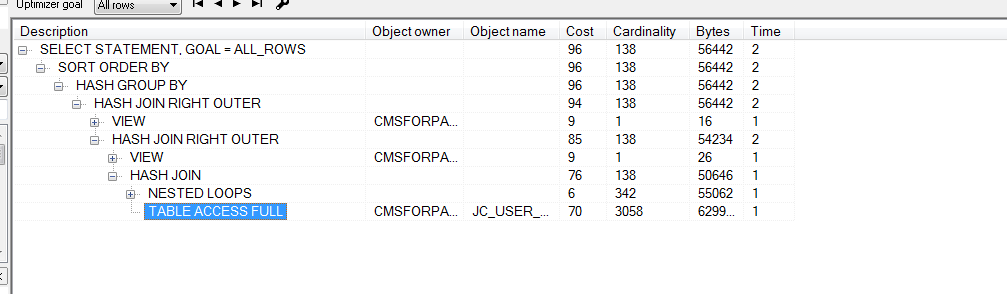
f5 查看下执行计划 看下性能瓶颈在哪 对应的优化
给对应的过滤字段添加索引 如:STEPMEDAL.USER_ID , TOTAL.USER_ID ,WACOM.WA_ID ,REL.WA_ID等等
嵌套太多层子查询,会造成性能急剧下降,建议每一步分开查询,可以将每一步的结果存入临时表中,例如:
1、create table A select a,b,c,d from sourcetable where a>111;
2、create table B select a,b,c,count(1) from A where d>10 group by a;
...
建议写入脚本当中,再执行。
目前 最费资源的 查询是如下 有优化的方法吗
SELECT USERINFO.USER_ID,
EXT.REALNAME,
NVL(EXT.USER_IMG, 0) USER_IMG,
TO_CHAR(ACTI.START_DATE, 'YYYY-MM-DD') START_DATE,
TO_CHAR(ACTI.END_DATE, 'YYYY-MM-DD') END_DATE
FROM JC_USER_EXT EXT,
JC_USER USERINFO,
JC_USER USERDEPART,
WALK_ACTIVITY_MAIN ACTI,
WALK_ACTIVITY_COMPANY_REL REL,
WALK_ACTIVITY_COMPANY_REL WACOM
WHERE ACTI.WA_ID = WACOM.WA_ID
AND REL.COMPANY_ID = USERDEPART.DEPART_ID
AND WACOM.WA_ID = REL.WA_ID
AND USERINFO.DEPART_ID = WACOM.COMPANY_ID
AND EXT.USER_ID = USERINFO.USER_ID
AND ACTI.STATE = 1
AND ACTI.STATUS = 1
AND EXT.JOB_TYPE = 1
AND USERDEPART.USER_ID = 12519
逻辑是查询该员工公司参加的有效活动下所有公司job_type=1 的员工信息
建索引 分区 。表数据量超过千万级 建子分区 增加执行进程数