JAVA如何对抓取到的html文本进行解析和数据处理
有个功能需要在网上抓取一些数据,本身数据格式是纯html格式的,但是后来别人网站的数据而是改变了,如下.我应该如何获取其中的某个节点的数据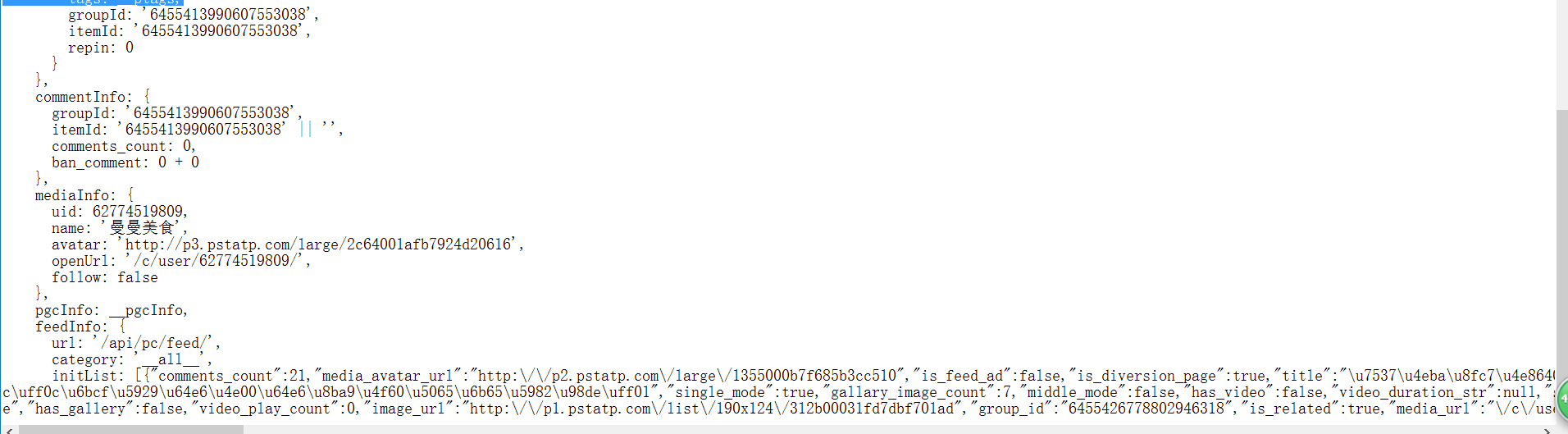图片说明](https://img-ask.csdn.net/upload/201708/18/1503043666_578750.png)图片说明](https://img-ask.csdn.net/upload/201708/18/1503043657_25325.png)
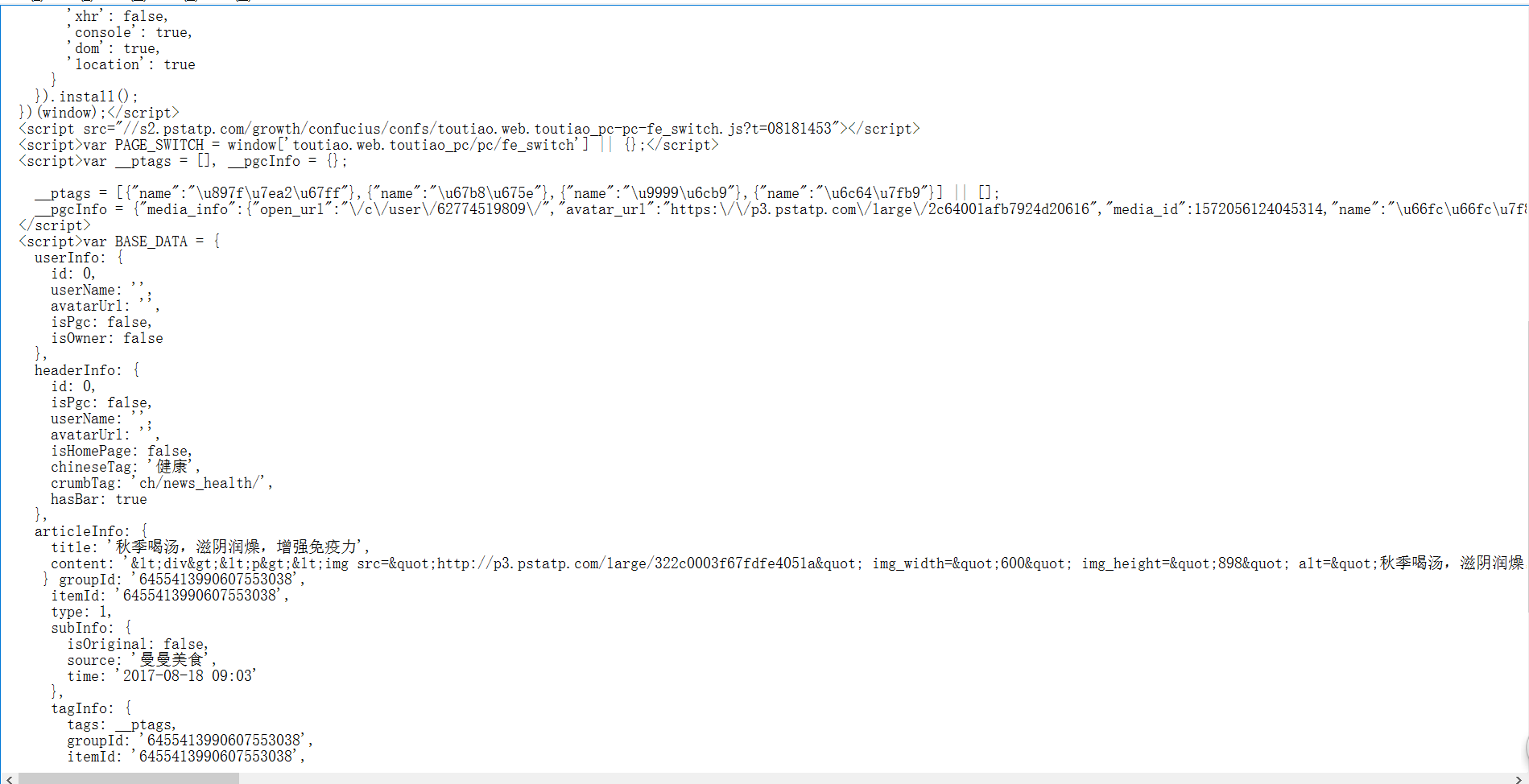
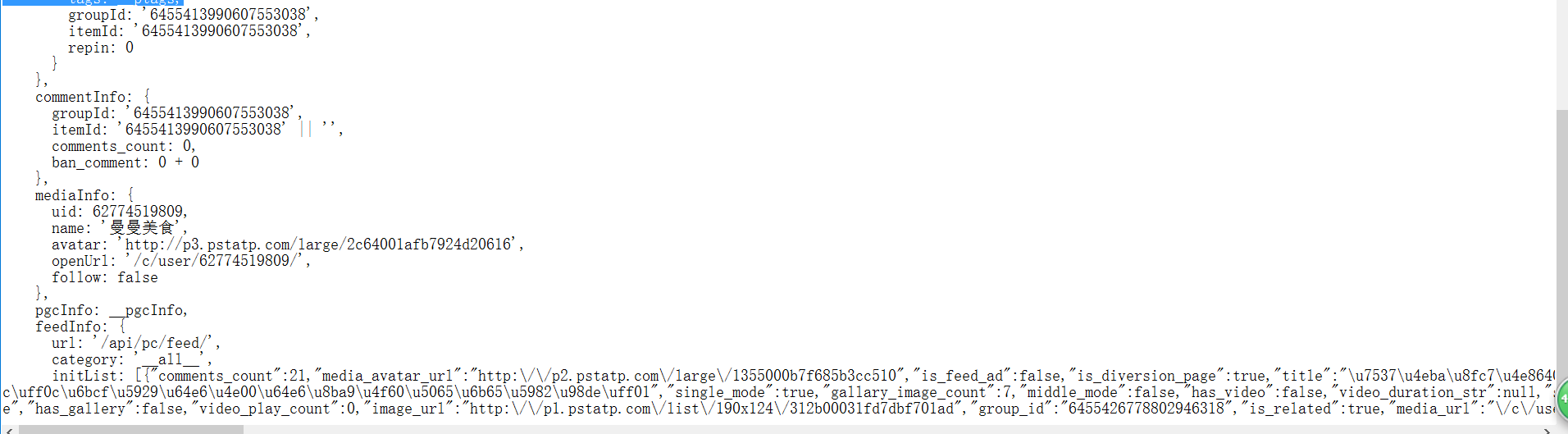
如上就是抓取的数据结构,现在想要获取js中的articleInfo中的数据.尝试了很多办法都不能解决.希望大家能帮下忙1
正则表达式,,,提取字符串信息相当靠谱
你要看看 Jsoup jsoup 是用来抓取页面的 这里有讲解http://www.open-open.com/jsoup/
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API (复制粘贴的 看看吧)
javax.xml.parsers.DocumentBuilderFactory factory =
javax.xml.parsers.DocumentBuilderFactory.newInstance();
factory.setIgnoringComments(false);
factory.setIgnoringElementContentWhitespace(false);
factory.setValidating(false);
factory.setCoalescing(false);
DocumentBuilder builder = factory.newDocumentBuilder();
return builder.parse(xmlfile);
解析成Document想干啥 干啥
其实html页面内容就是一个xml嘛 直接用Document解析