我最近考研需要这个网站的视频,想用python爬下来。
这个网站的请求视频的地址好像是用代码生成的,而且需要手动点击才能抓到,抓包一个一个来好慢啊!!
后来发现这个网站的flash播放器的预览图地址和视频请求地址很相似,可是虽然这个预览图是默认加载的,可不过也只能在chrome的抓包里看到这个单独页面请求地址
最关键的问题还是这里的地址没有规律,地址有两个参数(图里面显示出来的那一段),有一个死活找不出来,求大神帮忙分析一下源代码,找出来这个地址的生成方法
如果有人能够有别的爬取的方法也可以的啊
网页地址:http://mooc.chaoxing.com/nodedetailcontroller/visitnodedetail?knowledgeId=757531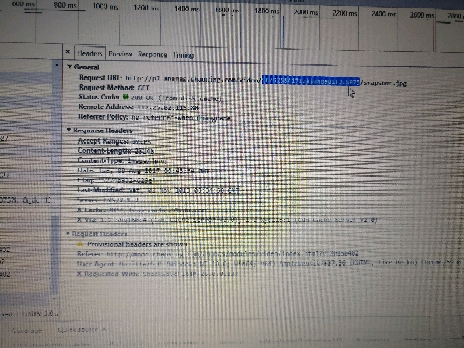
具体要抓那个视频,里面那么多的类别,用开发者工具点击视频看一下发的请求,提炼出来视频网址
没抓取过视频,稍微有点复杂。。。
](http://mooc.chaoxing.com/nodedetailcontroller/visitnodedetail?knowledgeId=757531!%5B%E5%9B%BE%E7%89%87%5D(https://img-ask.csdn.net/upload/201708/08/1502190679_257869.jpg)){kind=link}