selenium怎么定位到百度统计流量研究院里面的折线图中的文本呢。
怎么定位到元素,并获取到里面的text呢?求大神解答,感谢万分
没人吗
import requests
import json
url = "https://tongji.baidu.com/research/api/app/brand"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36",
"Content-type": "application/json;charset=UTF-8",
"Host": "tongji.baidu.com",
"Origin": "https://tongji.baidu.com",
"Referer": "https://tongji.baidu.com/research/app",
"Cookie": r'csrfToken=yVq5wgTIYKX52IYoxhWDK-Dx;'
}
data = {
"dateFormatType": "day",
"et": 1609430399999,
"osType": 0,
"st": 1606752000000,
"_csrf": "yVq5wgTIYKX52IYoxhWDK-Dx"
}
res = requests.post(url=url, headers=headers, data=json.dumps(data))
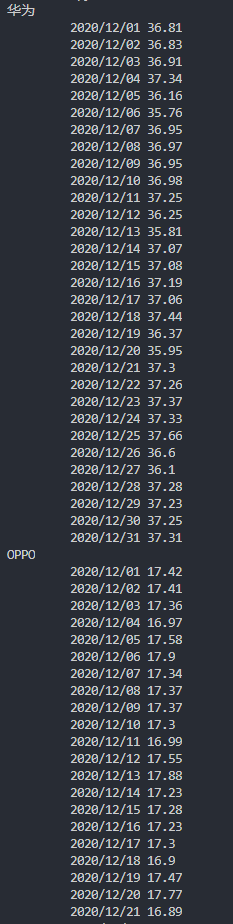
d = res.json()['data']['items']
print(d)
import requests
import json
url = "https://tongji.baidu.com/research/api/app/brand"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36",
"Content-type": "application/json;charset=UTF-8",
"Host": "tongji.baidu.com",
"Origin": "https://tongji.baidu.com",
"Referer": "https://tongji.baidu.com/research/app",
"Cookie": r'csrfToken=yVq5wgTIYKX52IYoxhWDK-Dx;'
}
data = {
"dateFormatType": "day",
"et": 1609430399999,
"osType": 0,
"st": 1606752000000,
"_csrf": "yVq5wgTIYKX52IYoxhWDK-Dx"
}
res = requests.post(url=url, headers=headers, data=json.dumps(data))
d = res.json()['data']['items']
for d2 in d:
print(d2['name'])
for d3 in d2['items']:
print('\t',d3['name'],d3['value'])
这个cookie和csrf要怎么获取的呢,我获取的为什么和你不一样呀?感恩。
浏览器Cookie 中 csrfToken 的值是网站随机生成的,每个浏览器生成的都不一样。
在python 代码中 csrfToken 的值你可以随便写,只要与 data 参数中 _csrf 设置一样的值就可以。