java 这种for循环写法 什么意思
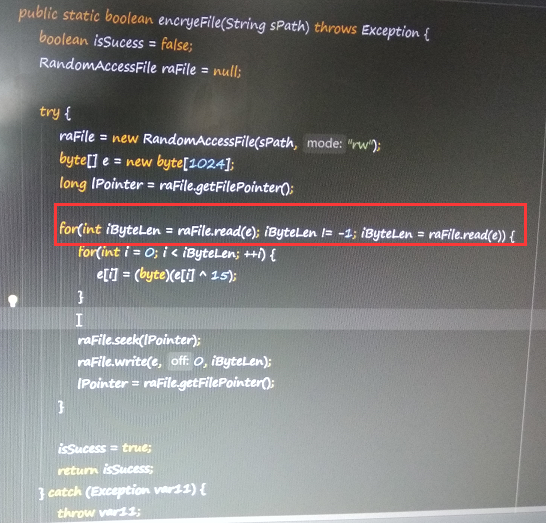
循环体的三个部分解释如下:
int iByteLen = raFile.read(e) //循环开始,读取raFile文件中1024个字节数据到e数组中,成功返回读取的字节数,失败返回-1。
iByteLen != -1 //循环判断条件,如上所述,当读取失败时,iByteLen == -1 ,退出循环。当读取成功时,iByteLen != -1 ,满足循环条件,继续循环。
iByteLen = raFile.read(e) //处理完上一次读取的1024个字节后,再次读取raFile文件中1024个字节数据到e数组中。
用心回答每个问题,如果对您有帮助,请采纳答案好吗,谢谢!
read(bytes)返回的是个整数,是每次填充给bytes数组的长度。
这个方法在按bytes数组读取文件。不等于-1是因为出现-1就说明文件已经读取结束了。
可以通过这个方法,进行循环读取文件内容,当read返回值为-1的时候,表示文件读取完毕,就可以显示文件内容,进行相应的操作。(百度搜到的)
和下面的 for(int i=0;i<ByteLen;i++)一个意思啊。
i++意思不就是i=i+1吗。
现在变成了iByteLen =raFile.read(e)
就是循环读取数据到e,每次都判断是否读完数据,read返回-1的时候就是文件读取结束了
关于for循环的灵活运用,初始条件很好理解,变化条件也好理解。
不是说:中间条件判断必须是大于小于这些,只要是条件判断语句都可以的,它就是一个判断。
一般遇到这样的,可以尝试将相同的提取出来, 这样看起来就简单了.
read(new byte[1024]) 每次读取1024字节 下次读取 就是从这次结束位置开始读取的. 当本次未读取到时 则返回 -1
这种我一般都会写成
int iByteLen;
while( ( iByteLen = raFile.read(e) ) != -1){ ... }