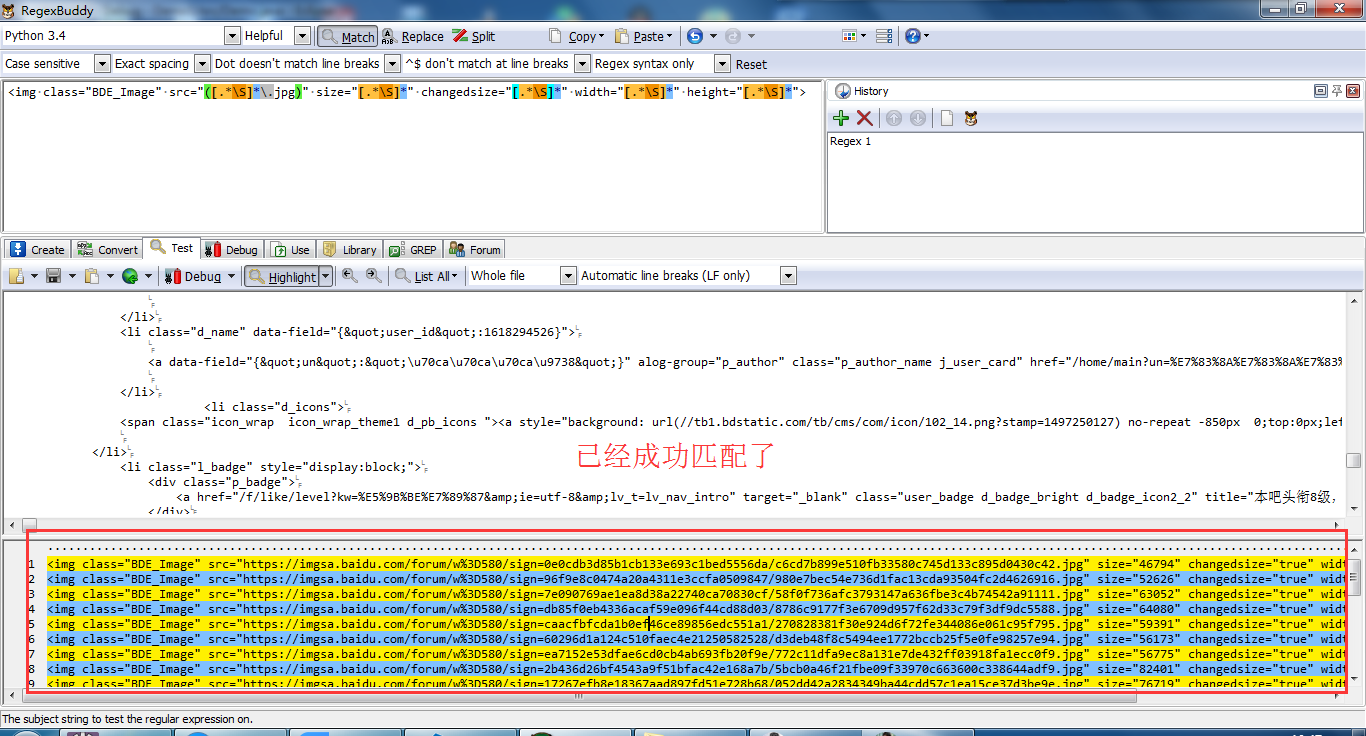
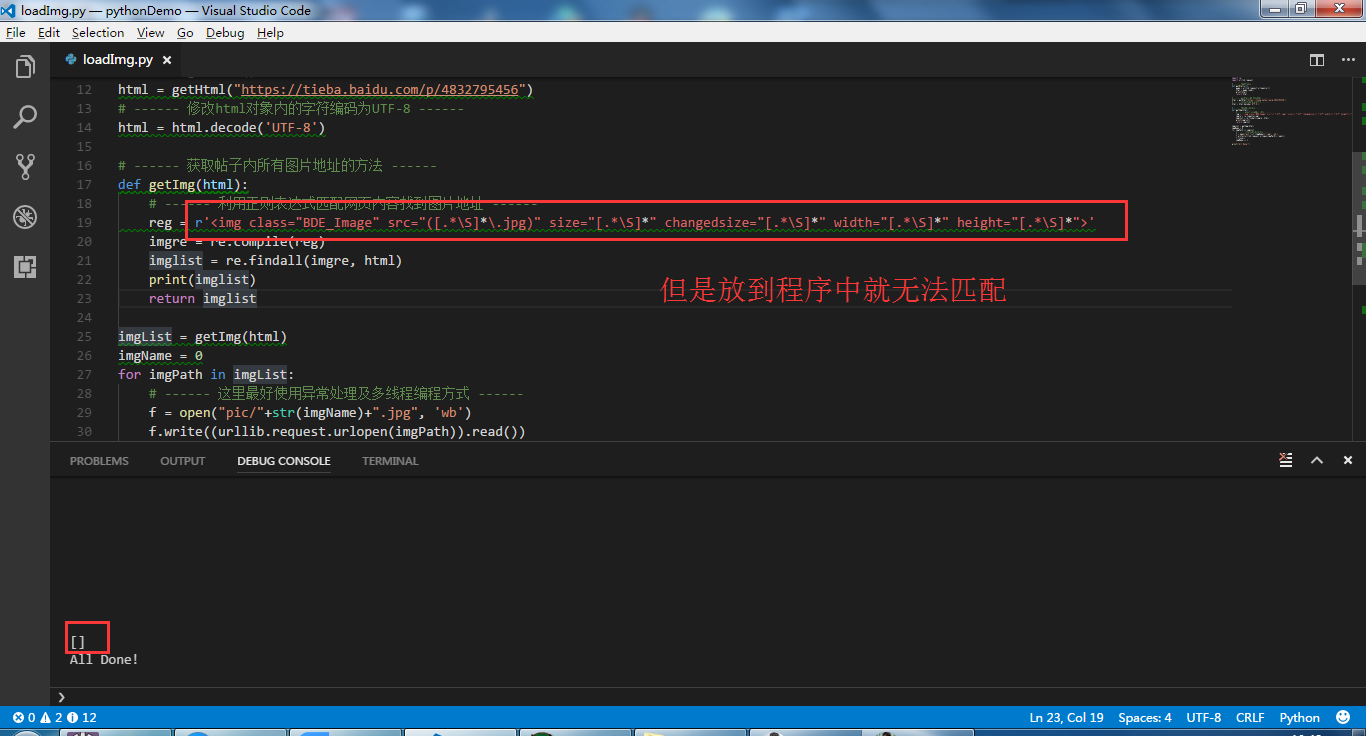
为什么我写的正则在测试工具中可以匹配,在代码中就无法匹配
经过不断的测试
找到了原因
如果我把目标html,在py中拼接成字符串,然后用正则去匹配,就可以匹配成功
如果不这么做,用urlopen远程去读取html,然后在用正则去匹配,就会匹配失败
找到了原因
如果我把目标html,在py中拼接成字符串,然后用正则去匹配,就可以匹配成功
如果不这么做,用urlopen远程去读取html,然后在用正则去匹配,就会匹配失败
直接考的正则还是右键复制为python?
看你的编译环境中,对转移字符的是如何使用的。比如:\,是用一个还是2个。。。
是不是需要转义一下\
请问你是如何拼接为字符串的,是直接str函数转换还是怎样?