乱码问题,网页编码是GB2312,PHP的
通过FIDDLER抓包,发现一段中文文字内容假如是
“想了解下最近的进口车中,夏朗有没有五座的”
POST以后,协议分析出来,POST的上面字符已经转为乱码
通过十六进制来看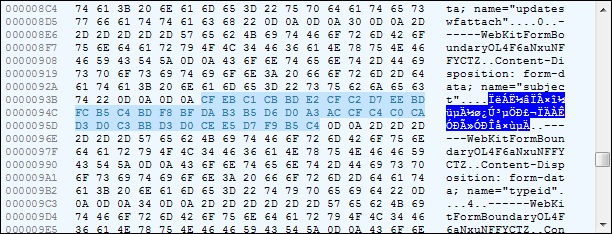
内容为
BASE64
z+vBy73iz8LX7r38tcS9+L/as7XW0KOsz8TAytPQw7vT0M7l1/m1xA==
十六进制
byte[] arrOutput = { 0xCF, 0xEB, 0xC1, 0xCB, 0xBD, 0xE2, 0xCF, 0xC2, 0xD7, 0xEE, 0xBD, 0xFC, 0xB5, 0xC4, 0xBD, 0xF8, 0xBF, 0xDA, 0xB3, 0xB5, 0xD6, 0xD0, 0xA3, 0xAC, 0xCF, 0xC4, 0xC0, 0xCA, 0xD3, 0xD0, 0xC3, 0xBB, 0xD3, 0xD0, 0xCE, 0xE5, 0xD7, 0xF9, 0xB5, 0xC4 };
实际显示为
ÏëÁ˽âÏÂ×î½üµÄ½ø¿Ú³µÖУ¬ÏÄÀÊÓÐûÓÐÎå×ùµÄ
我想问问这是什么编码。无从下手呢。
没有C币了,大伙看看,这应该挺有挑战的。
确认是中文么?很像是韩文的编码。
应该不是韩文。
我把BASE64的值转UTF-8,可以得到原先的中文。
但关键是,这个乱码是什么情况。怎么表现出来的。
unicode编码,英文是一对一的,但是中文占两个字符,所以它在编码的时候把中文一个字给拆成了两半,就变成了现在这样类似俄文的乱码了。