机器学习中整合不同预测方法的公式的含义
我运用机器学习的方法来预测两个蛋白质是否互作,而目前有4种基于氨基酸序列的编码方法结合SVM构成4种预测方法。我参考了别人的文献用下面的公式对4种方法进行一个整合,希望整合后能够比单种预测方法的预测精度要高。
每一个样本运用的公式如下: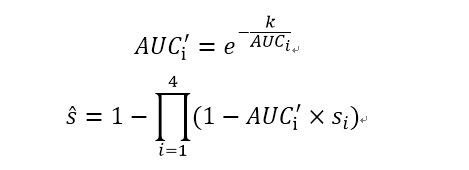
这里的s_i指的是每个样本用第i种方法预测后的得分,〖AUC〗_i指的是所有样本用第i种预测方法预测后的得分做出ROC曲线下的面积,s ̂为整合后每个样本的分数。
我不明白的地方是,这两个公式背后到底蕴含着什么意义和道理,为何要这样进行处理?