创建一个对象,他在堆内存中还是在栈内存中
Person p =new Person(“张三”,20);
这样的,我可不可以这样理解new Person(“张三”,20)在堆内存中创建,分配内存地址。
Person p 在栈内存中创建,然后把堆内存中的内存地址付给栈内存中的p变量
我这样理解有错误吗
你根本什么也没有理解,你只是在背绕口令。你需要理解什么呢?你需要理解为什么有堆栈?堆栈是干嘛的。当你使用函数的时候,函数中定义的每个变量都需要找地方存储。函数的调用是可以递归的,也就是说一个函数可以调用自身。
那么会出现什么问题呢?
函数中定义的局部变量存在多个副本,看下面的例子:
int foo(int n)
{
if (n == 0) return 0;
int x = foo(n - 1);
return x + n;
}
当我们调用foo(10)的时候,这个函数中虽然只有一个局部变量x,但是因为递归的关系,它存在同时存在9个的情况。
很明显,这种情况我们用一个可以一端扩展/收缩的数据结构,也就是堆栈去存储是最简单的。当函数每次调用下一层,就扩张,反之就收缩。
因此可以得到一个基本的结论,那些函数中定义的局部变量,一定是存放在堆栈上的。除此之外的变量,也就是同一个变量名,它在内存中没有副本的,就放在堆上。
这个是JVM运行时数据区的一个简单图解,我觉得这个方便楼主进行理解:
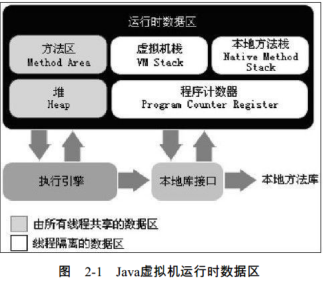
虚拟机栈 中的局部变量表会记录对象引用,就是reference类型,它不一定是对对象在堆中的直接地址的引用,也可能是对堆中句柄的引用(这取决于虚拟机的类型);
堆 主要储存对象的实例数据,但是对象的类型数据是储存在方法区的(也有一种说法是将堆和方法区都称为堆);
Person p =new Person(“张三”,20);
简单地说,声明Person p ,虚拟机在 方法区 中加载Person类信息,加载完毕后可以计算出Person对象的大致内存占用,之后在 虚拟机栈 中的 局部变量表中创建一个 对象引用,指向堆中的一片空内存区域;
之后执行new Person部分,虚拟机执行new指令,将Person实例对象加载到 堆 中,并对其进行初始化;
不同的虚拟机加载类可能过程上有一些不同,但大致过程就是这样;
其实楼主大致的理解是没有问题的,就是一些细节上可能有点偏差;
这个应该都是在堆中创建吧
确实应该如此。在虚拟机中执行的线程拥有独立的栈空间,每个线程操作自身的栈,线程的操作都直接依赖于栈,这也是为什么局部变量的作用域最小的原因,这也是堆中会存在没有引用的对象的原因。
首先,请问楼主,你这条语句能编译通过吗?
如果能编译过,你就不至于发问了。
Person p =new Person(“张三”,20);
这句如果能编译通过,需要考虑2个问题:
1.是构造函数
2.是重载赋值运算符
重点还是2重载赋值运算符
在类Person中 ,你需要实现 Person & operator=(const Person& )重载赋值预算符这个函数。
同时,要想让 Person p =new Person(“张三”,20);成立
你的类Person的重载赋值预算符中,起码有一个接受 Person类型的指针啥的吧?
构造函数的问题,我就不说了。
以上我说的是C++的情况。
如果你弄明白这个两个问题,你当然就明白,这个对象是在堆上还是栈上了。
Person p =new Person(“张三”,20);
上面的语句中变量 p放在栈上,用new创建出来的字符串对象放在堆上,而'“张三”,20'这个字面量是放在方法区的。
Person p =new Person(“张三”,20);
上面的语句中变量 p放在栈上,用new创建出来的字符串对象放在堆上,而'“张三”,20'这个字面量是放在方法区的。
较新版本的Java中,由于JIT编译器的发展和"逃逸分析"技术的逐渐成熟,栈上分配、标量替换等优化技术使得对象一定分配在堆上这件事情已经变得不那么绝对了。
String s1 = new StringBuilder("go").append("od").toString();
System.out.println(s1.intern() == s1); // trur
String s2 = new StringBuilder("ja").append("va").toString();
System.out.println(s2.intern() == s2);//false
你搞反了,栈中存地址,堆中存实例
感觉你的理解没错。以c#来讲,p在栈中,占有4个字节的内存,new Person(“张三”,20)声明出的实例在堆中,这个实例的地址存放在栈中的p里。
我也是这样理解的 p根据地址找到堆内存中的值