scrapy response解析不全打印结果缺失
# -*- coding: utf-8 -*-
import scrapy
from scrapy.conf import settings
class ContentSpider(scrapy.Spider):
name = "content"
allowed_domains = ["pkulaw.cn"]
start_urls = (
'http://www.pkulaw.cn/',
)
headers = settings.get('HEADERS')
surl = 'http://www.pkulaw.cn/fulltext_form.aspx?Db=chl&Gid=58178&keyword=&EncodingName=&Search_Mode=accurate'
def parse(self, response):
yield scrapy.Request(url=self.surl,
headers=self.headers,
callback=self.parse_con
)
def parse_con(self, response):
content = ''.join(response.xpath('.//*[@id="div_content"]').extract())
self.logger.info("--content--:%s" % content)
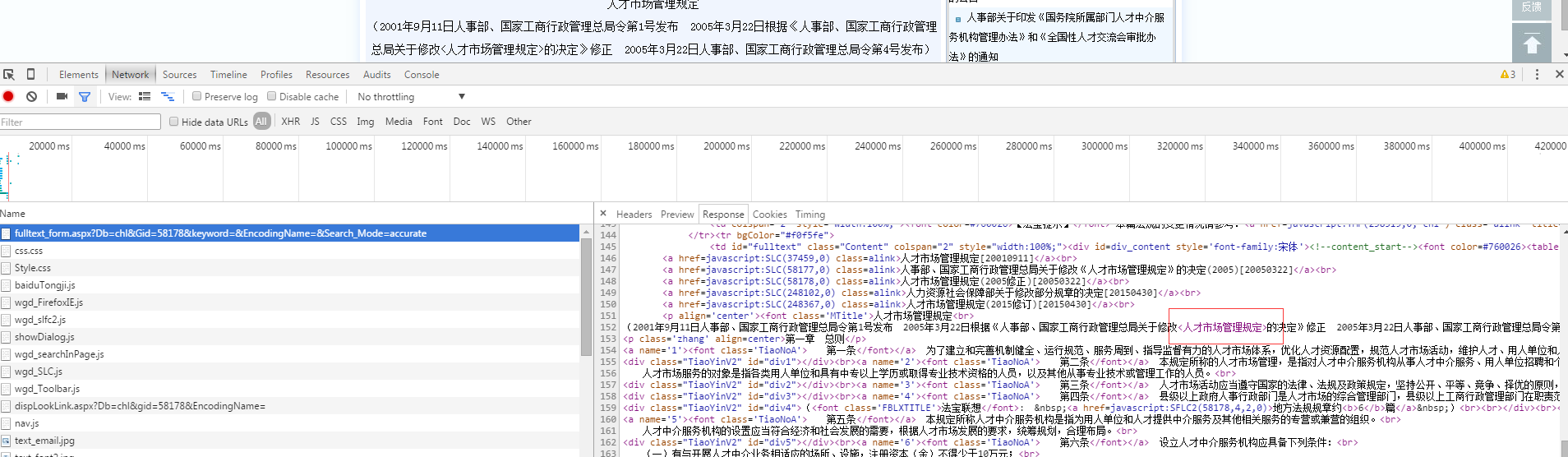
人才市场管理规定
(2001年9月11日人事部、国家工商行政管理总局令第1号发布 2005年3月22日根据《人事部、国家工商行政管理总局关于修改<人才市场管理规定>的决定》修正 2005年3月22日人事部、国家工商行政管理总局令第4号发布)
打印结果”<人才管理规定>“不存在,有什么解决办法吗
这个需要看看这个字符串是不是异步JavaScript插入的。直接的response中没有包含。