【Python自然语言处理】用Python载入语料库,已经都成功了,但无法进一步操作?
北师大学子一枚,在学习teven Bird的《Python与自然语言处理》,在学习2.1节最后的部分“载入你自己的语料库”,书中说了两种载入的方法,我用的是import plaintextCorpusReader的方法,最后都已经执行到下图这一步了:
但是接下来,自己试图统计每篇文档的平均每个句子的单词数,执行的时候怎么会报错了?找了好久都没找到症结所在/(ㄒoㄒ)/~~
希望各位大神不吝赐教啊……鄙人刚刚入nlp的坑,还是菜鸟级别……感激不尽!!!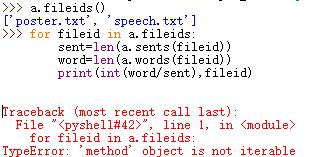
模块不支持迭代。a.fileids,数据结构是什么?a.fileids()