java.io.FileNotFoundException问题
package com.luceneheritrixbook.extractor.pconline.mobile;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Date;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.filters.AndFilter;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.filters.NotFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.ImageTag;
import org.htmlparser.tags.TableColumn;
import org.htmlparser.util.NodeList;
import com.luceneheritrixbook.extractor.Extractor;
import com.luceneheritrixbook.extractor.com163.Extract163Moblie;
import com.luceneheritrixbook.util.StringUtils;
public class ExtractPconlineMoblie extends Extractor {
public void extract() {
BufferedWriter bw = null;
//创建属性过滤器
NodeFilter attributes_filter = new AndFilter(new TagNameFilter("td"),
new OrFilter(new HasAttributeFilter("class", "td1"),new HasAttributeFilter("class", "td2")) );
//创建标题过滤器
NodeFilter title_filter = new TagNameFilter("h1");
/* NodeFilter title_filter = new AndFilter(new TagNameFilter("h1"),
new AndFilter(new HasAttributeFilter("class", "praameters"),
new NotFilter(new HasAttributeFilter("width"))));
*/
//创建图片过滤器
NodeFilter image_filter = new AndFilter( new TagNameFilter("img"),
// new HasAttributeFilter("class", "product-img"));
new HasAttributeFilter("class", "bigimg"));
//提取标题信息
try {
//Parser根据过滤器返回所有满足过滤条件的节点
NodeList title_nodes = this.getParser().parse(title_filter);
//遍历所有节点
long num = title_nodes.size();
for (int i = 0; i < title_nodes.size(); i++) {
Node node_title=title_nodes.elementAt(i);
//提取标题信息
//TableColumn node = (TableColumn) title_nodes.elementAt(i);
//用空格分割节点内部html文本
String[] names = node_title.toPlainTextString().split(" ");
StringBuffer title = new StringBuffer();
//创建要生成的文本文件名
for (int k = 0; k < names.length; k++) {
title.append(names[k]).append("-");
}
title.append((new Date()).getTime());
//创建要生成的文件
String path = this.getOutputPath();
bw = new BufferedWriter(new FileWriter(new File(path+title+".txt")));
//获取当前提取页的完整URL地址
int startPos = getInuputFilePath().indexOf("mirror") + 6;
String url_seg = getInuputFilePath().substring(startPos);
url_seg = url_seg.replaceAll("\\\\", "/");
String url = "http:/" + url_seg;
System.out.println(url);
//写入当前提取页的完整URL地址
bw.write(url + NEWLINE);
for (int k = 0; k < names.length; k++) {
bw.write(names[k] + NEWLINE);
}
}
} catch (Exception e) {
e.printStackTrace();
}
//重置Parser
this.getParser().reset();
try {
//Parser根据过滤器返回所有满足过滤条件的节点
NodeList attributes_nodes = this.getParser().parse(attributes_filter);
for (int i = 0; i < attributes_nodes.size(); i++) {
//Parser根据过滤器返回所有满足过滤条件的节点
TableColumn node = (TableColumn) attributes_nodes.elementAt(i);
String name = node.getAttribute("class");
//提取属性名信息
String result = node.toPlainTextString();
if( name.equals( new String("td1") ))
{
bw.write(StringUtils.trim(result) + ":");
} else if( name.equals( new String("td2") ))
{
bw.write(StringUtils.trim(result) );
bw.newLine();
}
// System.out.println(result);
//提取属性值信息
// TableColumn nodeExt = (TableColumn) node.getNextSibling();
/*
//提取属性名信息
String result = getProp(
"
node.toHtml(), 1);
//属性里面包含有link标签的情况
if (result.indexOf("<") != -1)
result = getProp(
"(.*)",
node.toHtml(), 2);
//提取属性值信息
TableColumn nodeExt = (TableColumn) node.getNextSibling()
.getNextSibling();
*/
continue;
}
} catch (Exception e) {
e.printStackTrace();
}
// 重置Parser
this.getParser().reset();
try {
// Parser根据过滤器返回所有满足过滤条件的节点
NodeList image_nodes = this.getParser().parse(image_filter);
for (int i = 0; i < image_nodes.size(); i++) {
ImageTag node = (ImageTag) image_nodes.elementAt(i);
//获取当前节点的SRC属性值
String image_url = node.getAttribute("src");
//提取文件类型
String fileType = image_url.substring(image_url
.lastIndexOf(".") + 1);
//生成新的图片的文件名
String new_iamge_file = StringUtils.encodePassword(
image_url, HASH_ALGORITHM)
+ "." + fileType;
image_url = StringUtils.replace(image_url, "+", " ");
//利用mirror目录下的图片生成的新的图片
copyImage(image_url, new_iamge_file);
bw.write(image_url + NEWLINE);
bw.write(SEPARATOR + NEWLINE);
bw.write(new_iamge_file + NEWLINE);
System.out.println(image_url);
}
} catch (Exception e) {
e.printStackTrace();
}
try{
if (bw != null)
bw.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
运行结果:
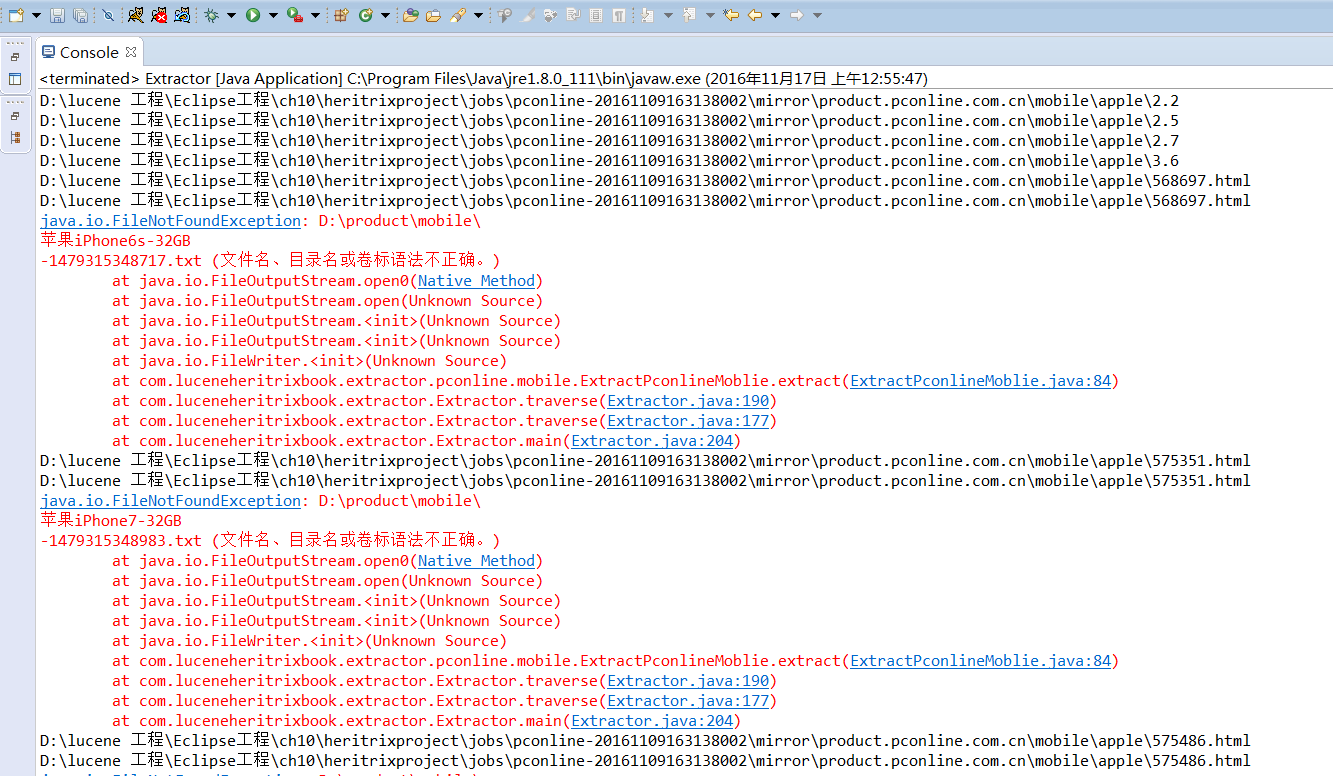
文件名中为什么会有回车符。。。。
一般都使用字符串的 替换来解决你这个 问题,可能路径会出现一些特殊的字符,我们可以通过replace 替换掉指定字符 。
或者你只保存名字,分割符使用 File.separator 这个会根据系统的不同生成相应的分隔符
调试下 Node node_title=title_nodes.elementAt(i); 和String[] names = node_title.toPlainTextString().split(" ");是否里面有换行
根据错误来看 你的文件地址+文件名不正常 还是仔细检查一下
电脑什么系统,确定有d盘吗
根据报错 应该是没找到对应的文件,调试看下,你文件地址对不对,和你电脑上存放文件路径比较下。
文件的路径跟你电脑上的路径对不上,好好检查一下
路径对不上, 好好检查一下
for (int k = 0; k < names.length; k++) {
title.append(names[k]).append("-"); //造成换行的原因是names变量引起的,names从html拆分出来时包含了\n
}
// ...
// 导致path+title+".txt" 组装文件名时发生了换行, 把names.replace("\n","") 就可以了。
bw = new BufferedWriter(new FileWriter(new File(path+title+".txt")));
new File(path+title+".txt") 你把这块先用一个字符串变量替换下,再传入到File中。顺便打印下输出的结果看看
打印原来的路径 ! u
u
结果会有换行
换个路径
能运行且文件也可以建好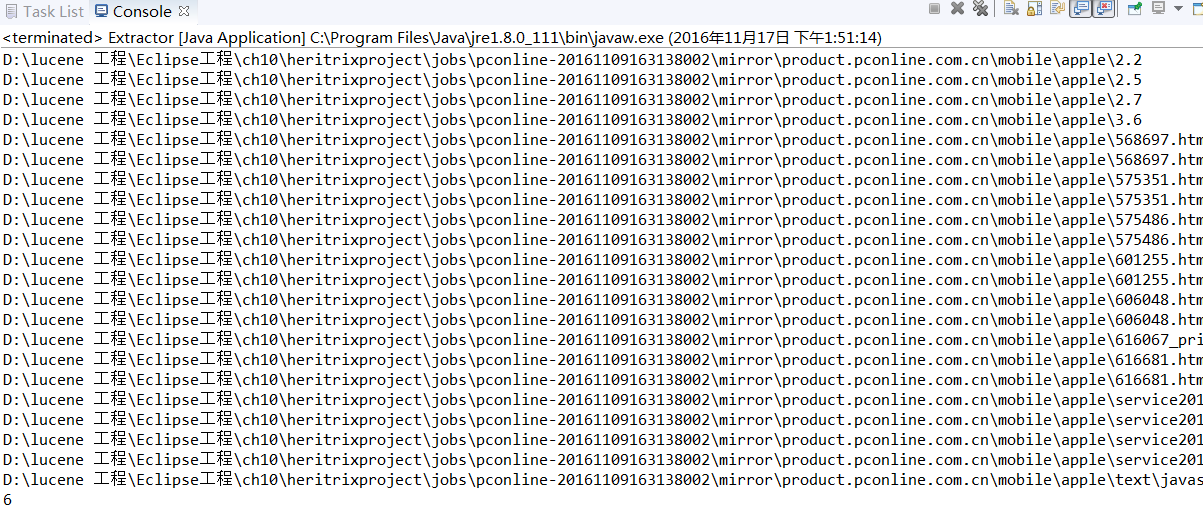
在对应的文件夹下没有相应的文件,因此出错
把出错的文件名截图贴出了看看罗
找不到路径,应该是你文件没有在这个路径下面啊。。。