MySql NOT EXISTS 查询
表结构:
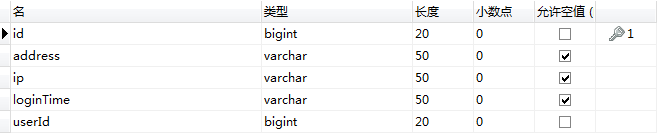
id和userID为单索引
以下查询用时2.36秒
SELECT ull.* FROM userLoginLog ull WHERE NOT EXISTS
(
SELECT 1 FROM userLoginLog
WHERE 1=1
AND ull.userId = userId
AND id > ull.id
)
以下查询用时0.1秒
SELECT ull.* FROM userLoginLog ull WHERE NOT EXISTS
(
SELECT 1 FROM userLoginLog
WHERE 1=1
AND ull.userId = userId
AND id < ull.id
)
为什么差距这么大?
你可以试试先执行下面的在执行上面的看看用时。
条件 id > ull.id与条件id < ull.id所覆盖的数据量不一样,可以根据实际情况改变写法来获取更高效的sql语句。
参考自:EXISTS、IN与JOIN的用法区别 http://www.data.5helpyou.com/article307.html
执行应该差不多,主要是返回的数据量影响
比如:返回1条同100条结果集速度
你可以把
SELECT ull.*改为 select count(*)
比较时间
返回的结果集数据量是一样的
结果集一样? 那你看id 和ull.id之间的差距
我觉得跟你目前表里的数据排序有关,如果安装id升序排列的话,那么结果就是当前这样。
查询结果数据量不一致产生的差异, 另外你可以使用explain 分析sql如何使用索引来处理查询语句。