python中sklearn.svm.SVR,模型预测得出的结果都是一个值,请高手指点迷津。
部分代码如下:
feature_set_train=feature_set[:6000]
result_set_train=result_set[:6000]
svr_model=SVR(C=1024,gamma=0.5)
svr_model.fit(feature_set_train,result_set_train)
feature_set_=feature_set[5900:6020]
result_set_ = result_set[5900:6020]
result_set_predict=svr_model.predict(feature_set_)
得出的拟合结果是对训练数据部分数据进行预测,则预测效果很好,对测试数据进行预测部分则得出的结果都为一个值,不明白是为什么?画图如下: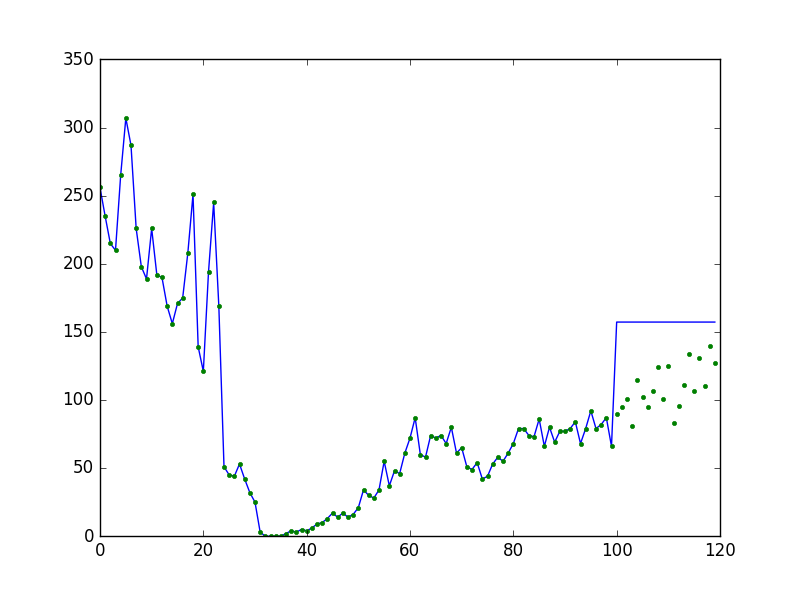
图中0-100为训练数据预测情况,100-120为测试数据预测情况。
模型中的数据为20维输入,1维输出
其中只有训练点输入模型进行预测才能得出有效值,其他点输入模型进行预测都得到的是同一个值。
谢谢各位的热心帮助,问题解决了,最后好像是因为样本数据没有归一化导致的。由于维度太大,如果不采用归一化处理的话,各个点间的距离值将非常大,故模型对于待预测点的预测结果值都判为同一个值。
训练时归一化
scale = StandardScaler()
scale_fit = scale.fit(x)
x = scale_fit.transform(x)
预测时用同一个scale_fit归一化,再预测
x_ = scale_fit.transform(x_)
clf.predict(x_)
您好,请问您这这个完整的SVR的程序方便分享一下吗?我最近正在做这方面的学习,需要SVR的源码,可以的话麻烦联系我一下,我会给予酬谢,非常感谢
您好,请问你如何做归一化处理?我用了sklearn.preprocessing.scale()处理后再预测还是出和你描述一样的问题
我也遇到一样的问题了,您解决了吗?
C 为什么设置成1024 改一下C的值试一试
还有一个可能的原因在于,你使用的训练数据与预测数据是完全分段的,真正进行模型拟合·时,使用的训练数据与预测数据应当是
相互包含,或随机抽取的,这样才能得到类似插值的结果。