android怎么用正则表达式,截取html中的<p>内容?
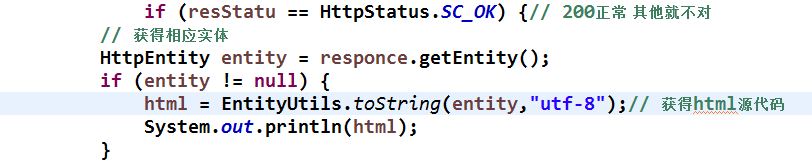图片说明](https://img-ask.csdn.net/upload/201604/23/1461402579_551942.png)
图片说明](https://img-ask.csdn.net/upload/201604/23/1461402657_173524.png)
用Pattern和Matcher
正则表达式:
String reg = "<p.*?>.+?</p>";
申明的时候忽略大小写匹配。
不断的用Matcher的find来就行组个匹配。
最后获取到的就是p标签了
Pattern pattern=Pattern.compile("
(.+?)");Matcher matcher=pattern.matcher("你的内容");
if(matcher.find()){
System.out.println(matcher.group(1));
}
我的土办法:
String [] contents=html.spilt("
String reg="
";
String content;
for(int i=0;i<contents.length;i++){
content=contents[i];
content[i]=content.subString(content.indexOf(reg)+reg.length,congent.length-1);
}
System.out.println(contents.toString());
我的土办法:
String [] contents=html.spilt("</p>");
String reg="<p style=\"text-indent:2em ; padding: 3px 0px ;\">";
String content;
for(int i=0;i<contents.length;i++){
content=contents[i];
contents[i]=content.subString(content.indexOf(reg)+reg.length,congent.length-1);
}
System.out.println(contents.toString());
直接用Jsoup解析HTML即可