java如何解析含有html内容的xml文件
是这样的,现在有个xml文件,实际上是个只有头部是xml标签的文件,内容主体是html写成的,现在想要解析这个xml文件,提取其中的数据,不知该用何种方法。
试过dom4j和jsoup,这两个一个适合用来解析纯xml文件,一个适合解析纯html文件,但是不知如何解析嵌套在xml文件里的html文件。这是我要解析的xml文件截图一部分: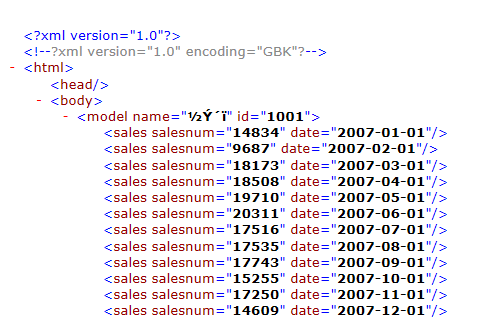
这是xml文件的一部分:
<?xml version="1.0"?>
-
-
……
请各路大神指点迷津。
http://blog.csdn.net/javaxiaochouyu/article/details/6889140
这个有好几种方法的,可以用dom4j,可以用sax,也可以用jdom;这几种方式各种特点,你需要根据业务去判断用哪个
需要先从html的整体文本中正则捕获出xml文件,然后才能选用dom4j之类的解析器进行解析
Elements urlem = dom.getElementsByTag("model")
e.select("[salesnum=14609]").attr("date")
jsoup 不知道行不行。