为何用Python做爬虫时抓取下来的页面跟源代码不一样?
代码如下:
-*- coding:utf-8 -*-
import urllib
import urllib2
import re
baseURL = 'http://zhidao.baidu.com/question/491268910.html'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36'}
#request = urllib2.Request(baseURL)
request = urllib2.Request(url=baseURL,headers=headers)
response = urllib2.urlopen(request)
print response.read().decode("GBK")
我用上面的代码爬取一个百度知道的答案,把抓取到的信息打印出来为什么有的地方跟网页审查元素所显示的代码不一样?
网页原来的段落为:
这段话对应的源代码为: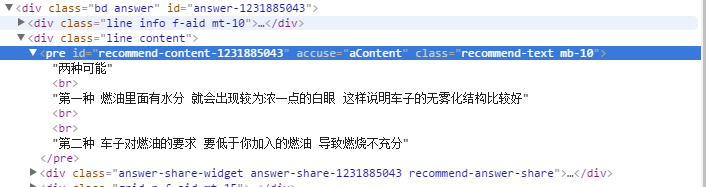
抓取网页信息后的对应的代码为:
我尝试了一个,在提取页面时,加载一个headers头部,但是结果还是不行,求各路大神指点,直接把解决办法附在评论区里,谢谢各路大神了。。。
要爬取js等动态生成的数据,可以使用神箭手云爬虫开发框架(shenjianshou.cn),只需要设置一下enableJS:true就可以自动爬取了,很方便!
我想要把网页采纳的答案给抓取出来,但是抓取到的信息里,为什么好多文字都被等代替了,怎么能让他直接显示原来的源代码啊
他很可能用了JavaScript动态加载页面。你获取的页面只是原来的html而已。
可以使用selenium尝试一下,我也遇到过这样的问题,用selenium就解决了
回答同样如上
你可以看看是否为动态加载页面,如果是,你可以使用selenium库的webdriver来动态爬取
首先在你的浏览器上安装对应的插件(例如我的浏览器是chrome)
driver = webdriver.Chrome
driver.get('website')
如果要想保存登录信息,可以去我的博文里看看