使用Python抓取下一页网页数据
怎么抓取一个无论怎么跳转其url都不变的网页?通过Requests和BeautifulSoup能实现吗?
http://www.szairport.com/frontapp/HbxxServlet?iscookie=C
另外其下一页的跳转指令是js写的,我该怎么通过这条指令跳转下一页,命令如下:
[<a href="javascript:void(0);" onclick="page.moveNext()">下一页</a>]
另附上我修改的代码;
import requests
import re
import BeautifulSoup
import json
a={"start":150,"limit":20}
r=requests.post("http://www.szairport.com/frontapp/HbxxServlet",data=json.dumps(a))
soup=BeautifulSoup.BeautifulSoup(r.text)
print soup
可以不用获取js的,通过form data,也可以获取指定页的数据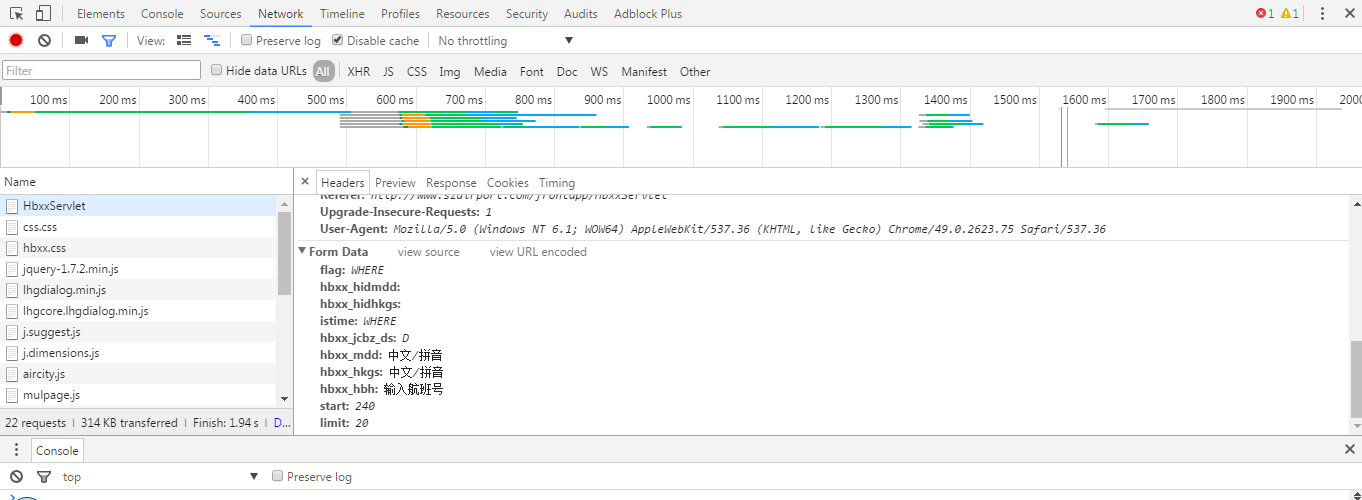
贴上我尝试的代码,新手见谅
import requests
import re
import BeautifulSoup
a={"Start":"150"}
r=requests.post("http://www.szairport.com/frontapp/HbxxServlet",data=a)
soup=BeautifulSoup.BeautifulSoup(r.text)
print soup
你可以先分析它跳转到下一页的URL格式,比如通过参数等,然后自己来构造对应的参数。发送请求
检查在network中发现Hbxxservlet的Query String Parameters的值是
flag=WHERE&hbxx_hidmdd=&hbxx_hidhkgs=&istime=WHERE&hbxx_jcbz_ds=D&hbxx_mdd=%E4%B8%AD%E6%96%87%2F%E6%8B%BC%E9%9F%B3&hbxx_hkgs=%E4%B8%AD%E6%96%87%2F%E6%8B%BC%E9%9F%B3&hbxx_hbh=%E8%BE%93%E5%85%A5%E8%88%AA%E7%8F%AD%E5%8F%B7&start=340&limit=20
构造http://www.szairport.com/frontapp/HbxxServlet?flag=WHERE&hbxx_hidmdd=&hbxx_hidhkgs=&istime=WHERE&hbxx_jcbz_ds=D&hbxx_mdd=%E4%B8%AD%E6%96%87%2F%E6%8B%BC%E9%9F%B3&hbxx_hkgs=%E4%B8%AD%E6%96%87%2F%E6%8B%BC%E9%9F%B3&hbxx_hbh=%E8%BE%93%E5%85%A5%E8%88%AA%E7%8F%AD%E5%8F%B7&start=1&limit500
修改start的值和limit的值,就能输出所有内容了,阿门,然后你就想抓啥抓啥吧