scrapy如何循环抓取所有类似的页面
我是刚刚开始学习爬虫,模仿网上一个例子自己写了一个,想循环抓取所有页面新闻标题和链接,但是只能抓取到起始页面的。
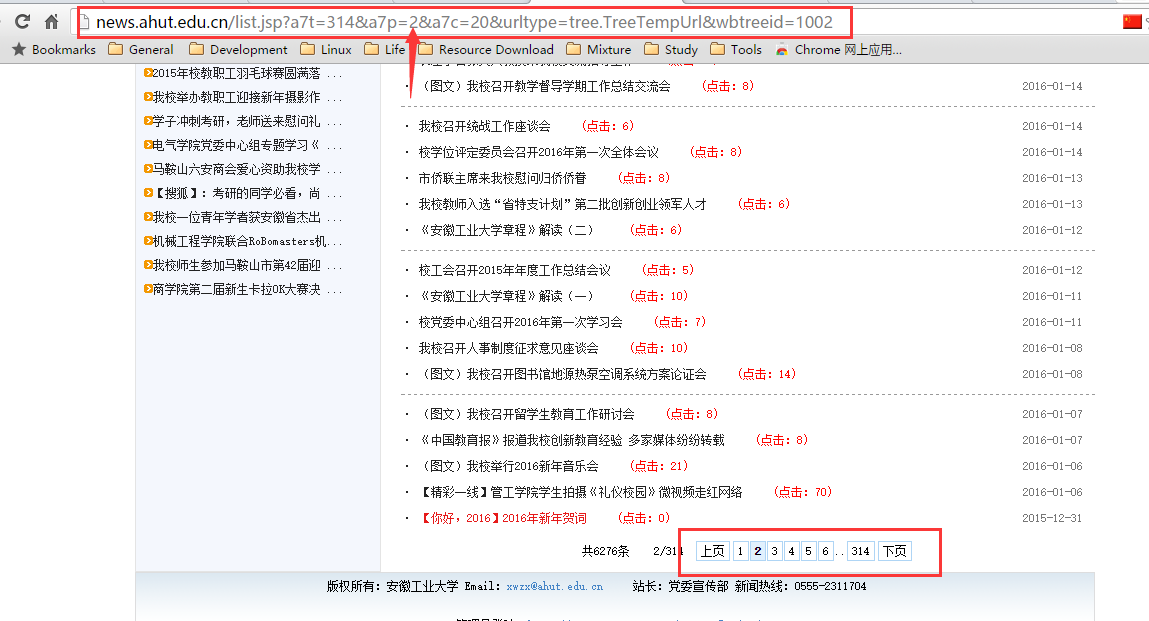
这是抓取的起始页面

从下面可以看到列表有很多,我想抓取所有的新闻条目,每一页的地址仅一个数字不同
spider文件夹下的关键代码如下所示
# -*- coding:utf-8 -*-
from scrapy.spiders import Spider
from scrapy.selector import Selector
from ahutNews.items import AhutnewsItem
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
class AhutNewsSpider(Spider):
name = 'ahutnews'
allowed_domains="ahut.edu.cn"
start_urls=['http://news.ahut.edu.cn/list.jsp?a7t=314&a7p=2&a7c=20&urltype=tree.TreeTempUrl&wbtreeid=1002']
rules=(
Rule(LinkExtractor(allow=r"/list.jsp\?a7t=314&a7p=*"),
callback="parse",follow=True),
)
def parse(self, response):
hxs = Selector(response)
titles = hxs.xpath('//tr[@height="26"]')
items = []
for data in titles:
item = AhutnewsItem()
title=data.xpath('td[1]/a/@title').extract()
link=data.xpath('td[1]/a/@href').extract()
item['title'] = [t.encode('utf-8') for t in title]
item['link'] = "news.ahut.edu.cn" + [l.encode('utf-8') for l in link][0]
items.append(item)
return items
http://www.tuicool.com/articles/jyQF32V
这个例子不错,代码没有注释,最后有一句if link[-1] == '4'这个等于4啥意思啊,返回条件吗?
这是我自己该写的,参考的是另外一个例子
```# -*- coding:utf-8 -*-
from scrapy.spiders import Spider
from scrapy.selector import Selector
from ahutNews.items import AhutnewsItem
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
class AhutNewsSpider(Spider):
name = 'ahutnews'
allowed_domains="news.ahut.edu.cn"
start_urls=['http://news.ahut.edu.cn/list.jsp?a7t=314&a7p=1&a7c=20&urltype=tree.TreeTempUrl&wbtreeid=1002']
# rules=(
# Rule(LinkExtractor(allow=r"/list.jsp\?a7t=314&a7p=*"),
# callback="parse",follow=True),
# )
def parse(self, response):
hxs = Selector(response)
titles = hxs.xpath('//tr[@height="26"]')
# items = []
for data in titles:
item = AhutnewsItem()
title=data.xpath('td[1]/a/@title').extract()
link=data.xpath('td[1]/a/@href').extract()
item['title'] = [t.encode('utf-8') for t in title]
item['link'] = "news.ahut.edu.cn" + [l.encode('utf-8') for l in link][0]
yield item
# items.append(item)
# return items
urls = hxs.xpath('//tr[@valign="middle"]/td[2]/div/a[last()]/@href').extract()
for url in urls:
print url
url = "http://news.ahut.edu.cn/list.jsp"+url
print url
yield Request(url, callback=self.parse)
**这是参考的例子**
#!/usr/bin/python
-*- coding:utf-8 -*-
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from csdnblog.items import CsdnblogItem
class CSDNBlogSpider(Spider):
"""爬虫CSDNBlogSpider"""
name = "csdnblog"
#减慢爬取速度 为1s
download_delay = 1
allowed_domains = ["blog.csdn.net"]
start_urls = [
#第一篇文章地址
"http://blog.csdn.net/u012150179/article/details/11749017"
]
def parse(self, response):
sel = Selector(response)
#items = []
#获得文章url和标题
item = CsdnblogItem()
article_url = str(response.url)
article_name = sel.xpath('//div[@id="article_details"]/div/h1/span/a/text()').extract()
item['article_name'] = [n.encode('utf-8') for n in article_name]
item['article_link'] = article_url.encode('utf-8')
yield item
#获得下一篇文章的url
urls = sel.xpath('//li[@class="next_article"]/a/@href').extract()
for url in urls:
print url
url = "http://blog.csdn.net" + url
print url
yield Request(url, callback=self.parse)
应该是一样的,但是我写的报错了,错误是

## 我查了一下,官方文档解释说是所该链接不符合当前的站点请求,可是该页面跟第一个是一样的,包含类似的结构,为什么就无法进行下去了呢,麻烦帮忙看一下