C# 使用ResponseStream下载文件部分,实际下载的文件部分比我要下载的文件部分小,什么原因?
C# 使用response.GetResponseStream下载文件某一部分,实际下载的文件部分 比 我要下载的文件部分小,什么原因?我要下载文件前50000000字节,实际下载只有49,909,760字节,代码如下:
class Program
{
public static void Main(string[] args)
{
PartDownload("http://192.168.1.104/jkbd.exe", @"C:\Users\WYQ\Desktop\Test\split\dt1.sp", 0, 50000000);
}
private static void PartDownload(string url, string filePath, Int64 start, Int64 end)
{
FileStream fs = new FileStream(filePath, FileMode.OpenOrCreate, FileAccess.ReadWrite);
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.AddRange("bytes", start, end);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream responseStream = response.GetResponseStream();
CopyStream(responseStream, fs);
responseStream.Close();
response.Close();
fs.Close();
}
public static void CopyStream(Stream inputStream, Stream outputStream, int bufferSize = 512*200)
{
BufferedStream bufferedInputStream = new BufferedStream(inputStream, bufferSize);
BufferedStream bufferedOutputStream = new BufferedStream(outputStream, bufferSize);
byte[] bs = new byte[bufferSize];
int len = 0;
while ((len = bufferedInputStream.Read(bs, 0, bufferSize)) != 0)
{
bufferedOutputStream.Write(bs, 0, len);
}
}
}
下载结果: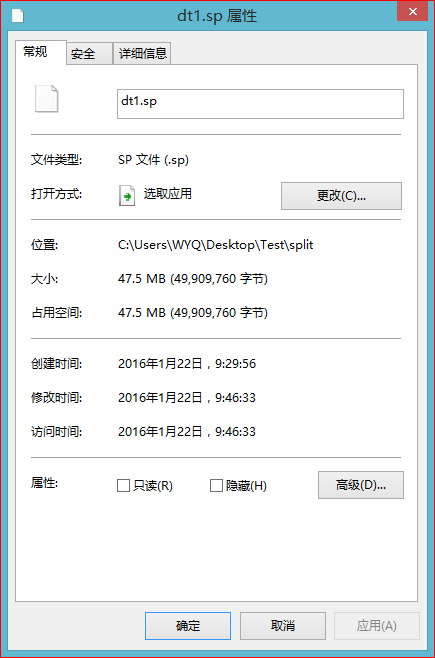
只有49,909,760字节,而我要下载文件前50000000字节。这个是什么原因导致的?
一个文件在不同的计算机上显示有可能不同
我是在同一台计算机上做的,服务器是我电脑windows8.1的iis8
如果不影响打开或者使用 这些差距可以忽略了
因为上传文件与下载文件是以字节流的方式进行 在进行字节流转换的过程中难免会丢失
就如同你用10/3.0会得到3.33333333333,然后你再乘以3 只能得到9.999999999而得不到10是一个道理